Amazon PDF Invoice Extractor
While web scraping is common, many high-value automation opportunities involve parsing documents like PDFs and Excel files. This is a large untapped market even in 2026.
This extractor will turn hours of manual work into seconds of automation.
We'll build a desktop tool that extracts key details from Amazon invoice PDFs such as:
- Place of Supply
- GST Identification Number (Think of it like Business ID)
- Document Number
- Document Date
Unlike our stock scraper, this extractor never opens a browser—it simply parses the file on the user's machine.
Creating it takes 4 simple steps:
- Install a PDF parsing package
- Write the extractor function
- Add the extractor to the server
- Create a file picker for PDF selection
Step 1: Install PDF Parsing Package
First, we need a tool to read PDF file content. We'll use electron-pdf-parse, a fork of the pdf-parse package that's designed to work seamlessly with Electron.
Open your terminal and install it:
npm install electron-pdf-parse
Step 2: Write the extractor function
Create a new file src/scraper/src/amazonPdfExtractor.ts and paste the code below.
// Import necessary libraries
import fs from "fs"; // For file system operations
import pdf from "electron-pdf-parse"; // For parsing PDF files
import { task } from "botasaurus/task"; // For task management
// Main function to extract data from the PDF text
async function extractFromText(text, pdfPath) {
// Utility function to format date from 'MM/DD/YYYY' to 'DD-MM-YYYY'
function formatDate(dateStr) {
const [month, day, year] = dateStr.split("/");
return `${day}-${month}-${year}`;
}
// Extract place of supply using regex
const placeOfSupplyMatch = text.match(/Place of supply : ([\w\s]+)\(/);
// Extract GSTIN using regex (reverse text to find it easily)
const gstinMatch = text.split("\n").reverse().join("\n").match(
/GSTIN : (\d{2}[A-Z]{5}\d{4}[A-Z]{1}\d{1}[Z]{1}[A-Z\d]{1})/
);
// Extract document number using regex
const documentNumberMatch = text.match(/Document Number\s*([A-Z0-9]+)/);
// Extract document date using regex
const documentDateMatch = text.match(/Document Date\s*(\d{2}\/\d{2}\/\d{4})/);
// Prepare the results object
const results = {
"Place of Supply": placeOfSupplyMatch ? placeOfSupplyMatch[1].trim() : null,
GSTIN: gstinMatch ? gstinMatch[1] : null,
"Document Number": documentNumberMatch ? documentNumberMatch[1] : null,
"Document Date": documentDateMatch
? formatDate(documentDateMatch[1])
: null,
};
return results;
}
// Function to read and extract data from a PDF file
async function extractData(pdfPath) {
const dataBuffer = fs.readFileSync(pdfPath); // Read the PDF file
const data = await pdf(dataBuffer); // Parse the PDF
return extractFromText(data.text, pdfPath); // Extract data from the parsed text
}
// Task definition for the Amazon PDF Extractor
export const amazonPdfExtractor = task({
// Name of the task - MUST match the input file name
name: "amazonPdfExtractor",
run: async function ({ data }) {
const files = data["files"]; // Get the list of files to process
const results: any[] = []; // Array to store results
// Process each file
for (const file of files) {
try {
const result = await extractData(file.path); // Extract data from the PDF
results.push(result); // Add the result to the array
} catch (error: any) {
console.error(error); // Log any errors
results.push({ failed: file, error: error.toString() }); // Add error details to results
}
}
return results; // Return the results
},
});
This code:
- Reads each PDF the user selects
- Extracts the full text using
electron-pdf-parse - Uses regular expressions to extract 4 fields:
- Place of Supply
- GST Identification Number
- Document Number
- Document Date
- Returns the results
Key points
- We use
task()instead ofplaywright()since no browser is needed - The function name
amazonPdfExtractorconnects to the input controls that will be defined ininputs/amazonPdfExtractor.js
Step 3: Add the extractor to the server
Now let's connect our extractor to the desktop app. Open src/scraper/backend/server.ts and add the extractor:
import { Server } from 'botasaurus-server/server';
import { amazonPdfExtractor } from '../src/amazonPdfExtractor';
Server.addScraper(amazonPdfExtractor); // 👈 makes it appear in the UI
Step 4: Create the file-picker input
Create a new file inputs/amazonPdfExtractor.js and paste following code:
/**
* @typedef {import('botasaurus-controls').Controls} Controls
* @typedef {import('botasaurus-controls').FileTypes} FileTypes
*/
const { FileTypes } = require('botasaurus-controls');
/**
* Renders the form users see on the Home page.
* @param {Controls} controls
*/
function getInput(controls) {
// Render a File Input for uploading PDFs
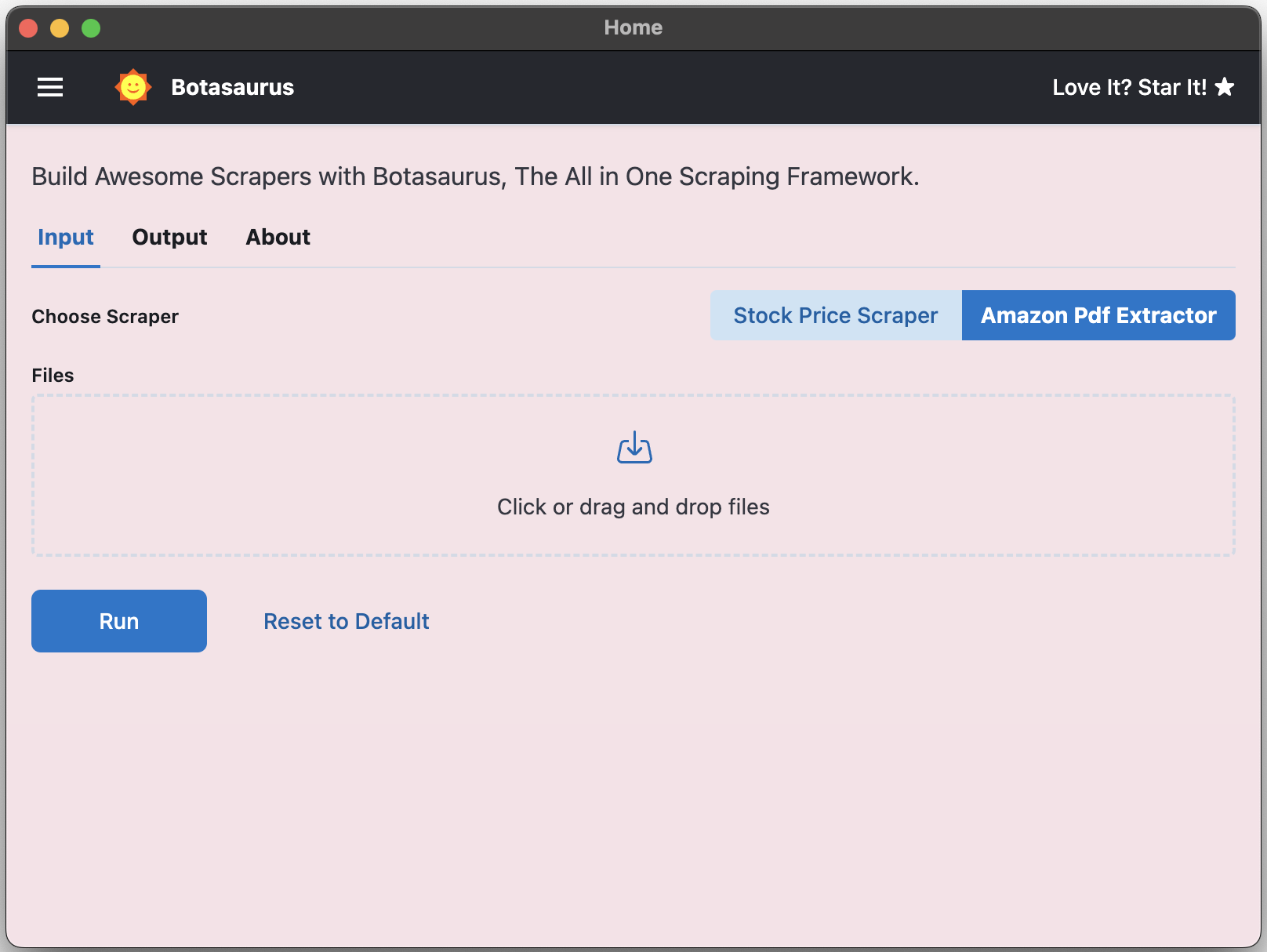
controls.filePicker('files', {
label: 'Invoice PDFs',
accept: FileTypes.PDF,
isRequired: true,
helpText: 'Drag one or more Amazon invoice PDFs here',
});
}
This creates a drag-and-drop file picker that only accepts PDF files:
Test with a Sample Invoice
Time to see your extractor in action:
- Reload the desktop app with
Ctrl/⌘ + R - Click on Amazon PDF Extractor
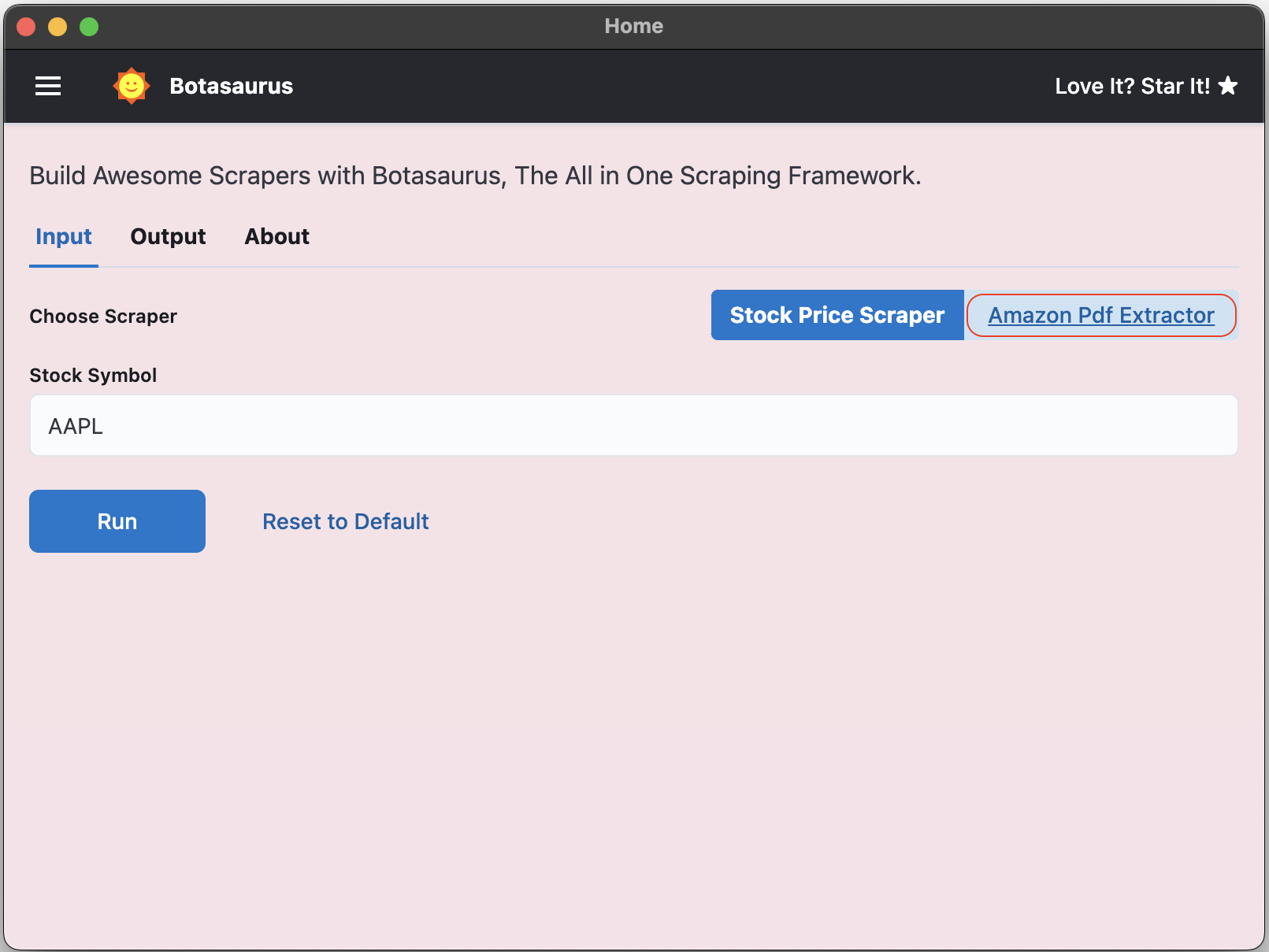
- Download this sample Amazon invoice PDF
- Drop the PDF into the file picker and click Run
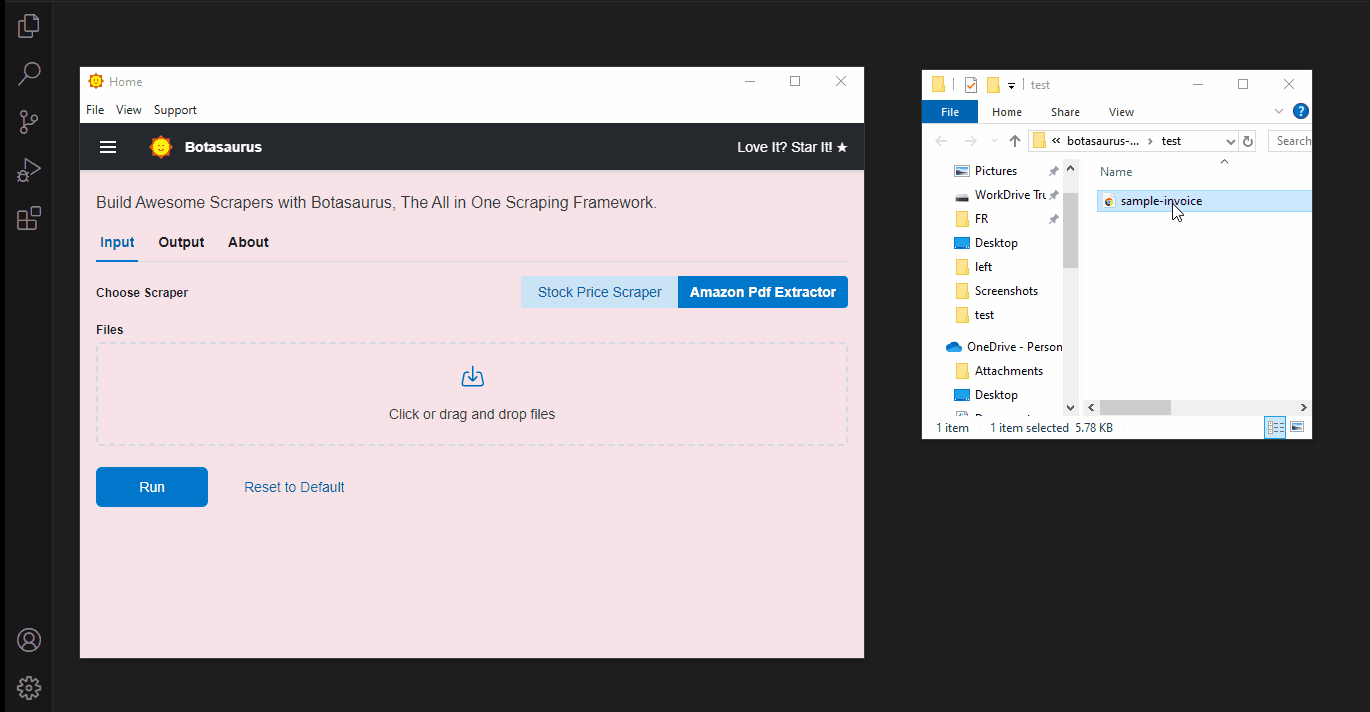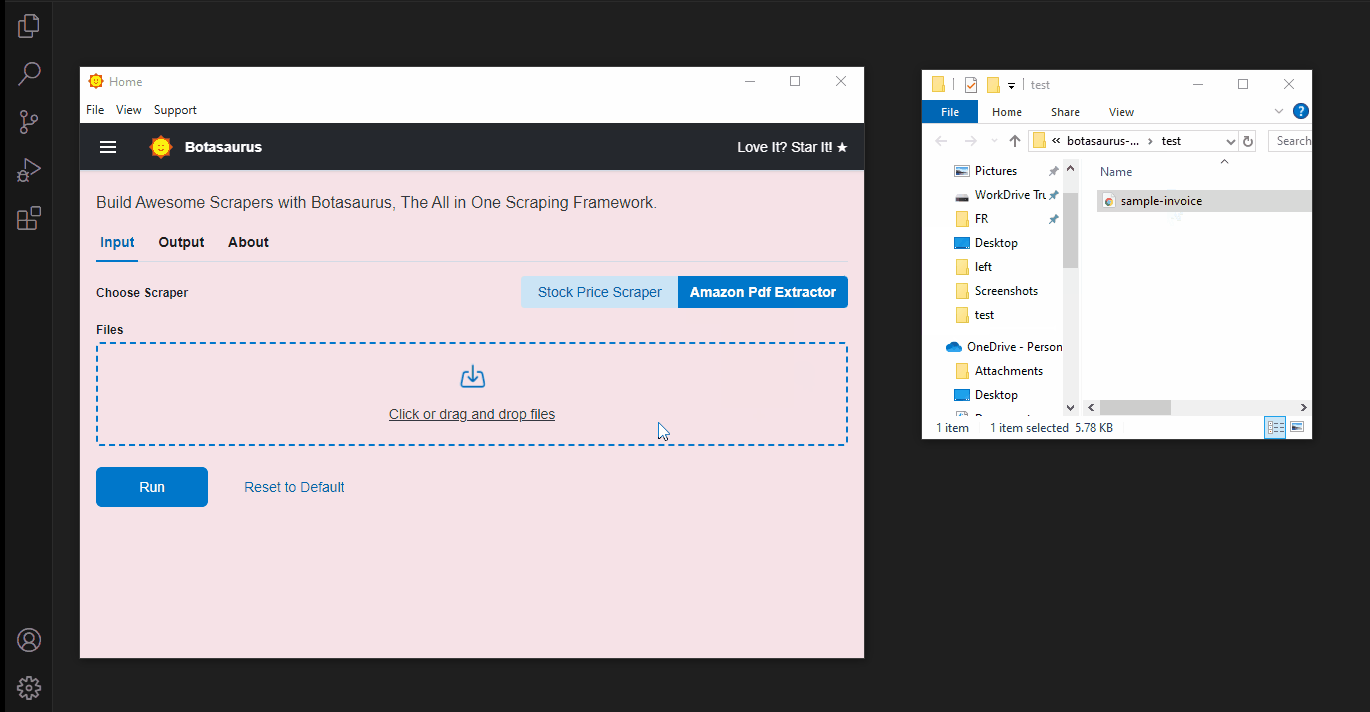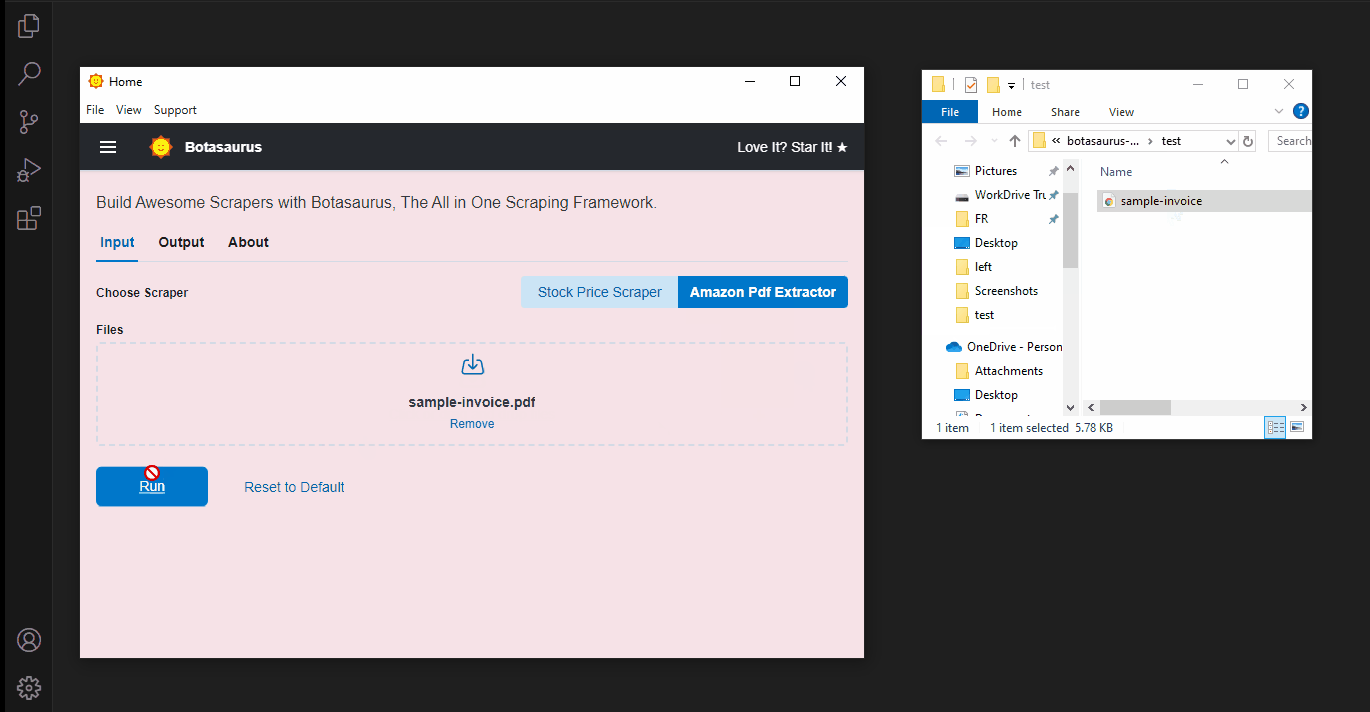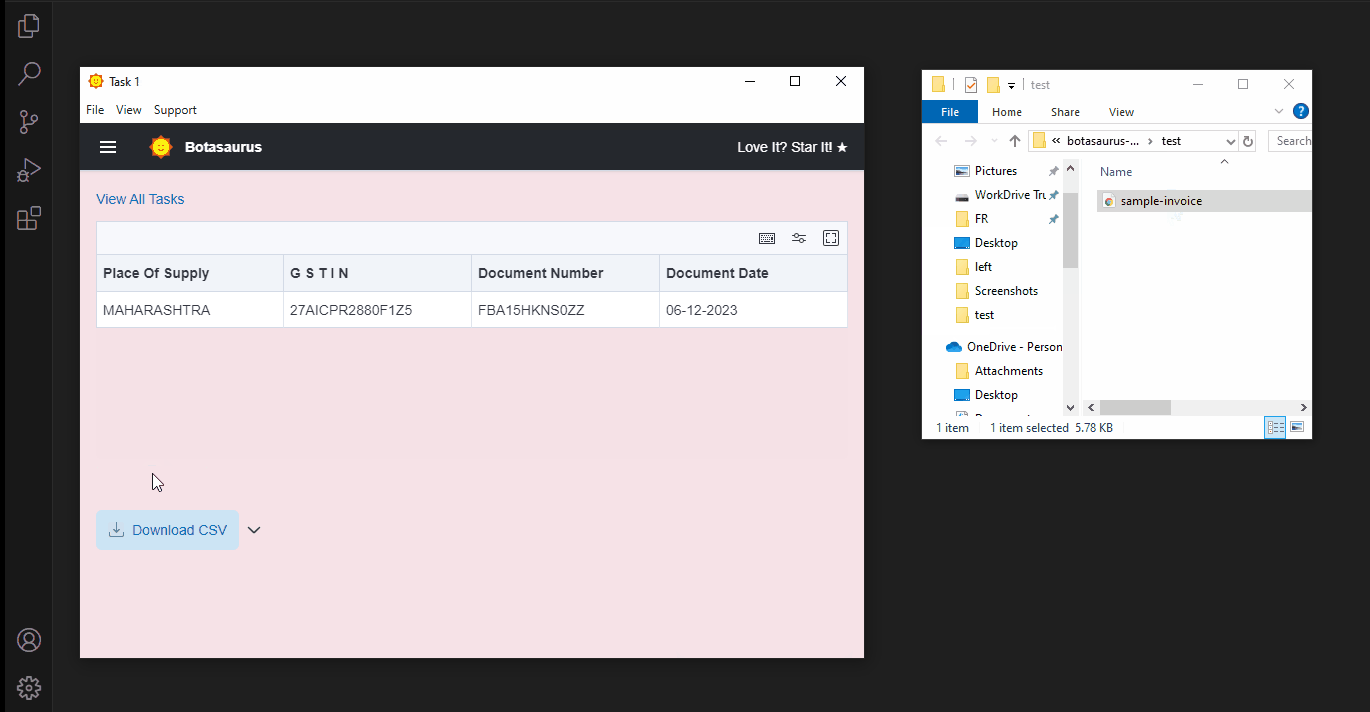
The app will parse the file and display a table like this:
| Place of Supply | GSTIN | Document Number | Document Date |
|---|---|---|---|
| MAHARASHTRA | 27AICPR2880F1Z5 | FBA15HKNSOZZ | 06-12-2023 |
🎉 Congratulations!
You've built a document processor that can extract data from hundreds of PDFs in seconds. The same approach works for any structured document—bank statements, receipts, and more.
Find the complete code for this tutorial, including the Stock Pricer Scraper and Amazon Invoice PDF Extractor, in the Botasaurus Desktop Tutorial GitHub Repository
You've now mastered both extraction styles: playwright for websites and task for local files and API calls.
Next, we'll explore advanced features like filtering, sorting, and custom data views to make your extractors even more easy to use.