What is Botasaurus?
In a nutshell
Botasaurus is an all in 1 web scraping framework built for the modern web. We address the key pain points web scrapers face when scraping the web.
Our aim it to make web scraping extremely easy and save you hours of Development Time.
Features
Botasaurus comes fully baked, with batteries included. Here is a list of things it can do that no other web scraping framework can:
- Anti Detect: Make Anti Detect Requests and Selenium Visits.
- Debuggability: When a crash occurs due to an incorrect selector, etc., Botasaurus pauses the browser instead of closing it, facilitating painless on-the-spot debugging.
- Caching: Botasaurus allows you to cache web scraping results, ensuring lightning-fast performance on subsequent scrapes.
- Easy Configuration: Easily save time with parallelization, profile, and proxy configuration.
- Time-Saving Selenium Shortcuts: Botasaurus comes with numerous Selenium shortcuts to make web scraping incredibly easy.
🚀 Getting Started with Botasaurus
Welcome to Botasaurus! Let’s dive right in with a straightforward example to understand how it works.
In this tutorial, we will go through the steps to scrape the heading text from https://www.omkar.cloud/.
Step 1: Install Botasaurus
First things first, you need to install Botasaurus. Run the following command in your terminal:
python -m pip install botasaurus
Step 2: Set Up Your Botasaurus Project
Next, let’s set up the project:
- Create a directory for your Botasaurus project and navigate into it:
mkdir my-botasaurus-project
cd my-botasaurus-project
code . # This will open the project in VSCode if you have it installed
Step 3: Write the Scraping Code
Now, create a Python script named main.py in your project directory and insert the following code:
from botasaurus import bt
@browser
def scrape_heading_task(driver: AntiDetectDriver, data):
# Navigate to the Omkar Cloud website
driver.get("https://www.omkar.cloud/")
# Retrieve the heading element's text
heading = driver.text("h1")
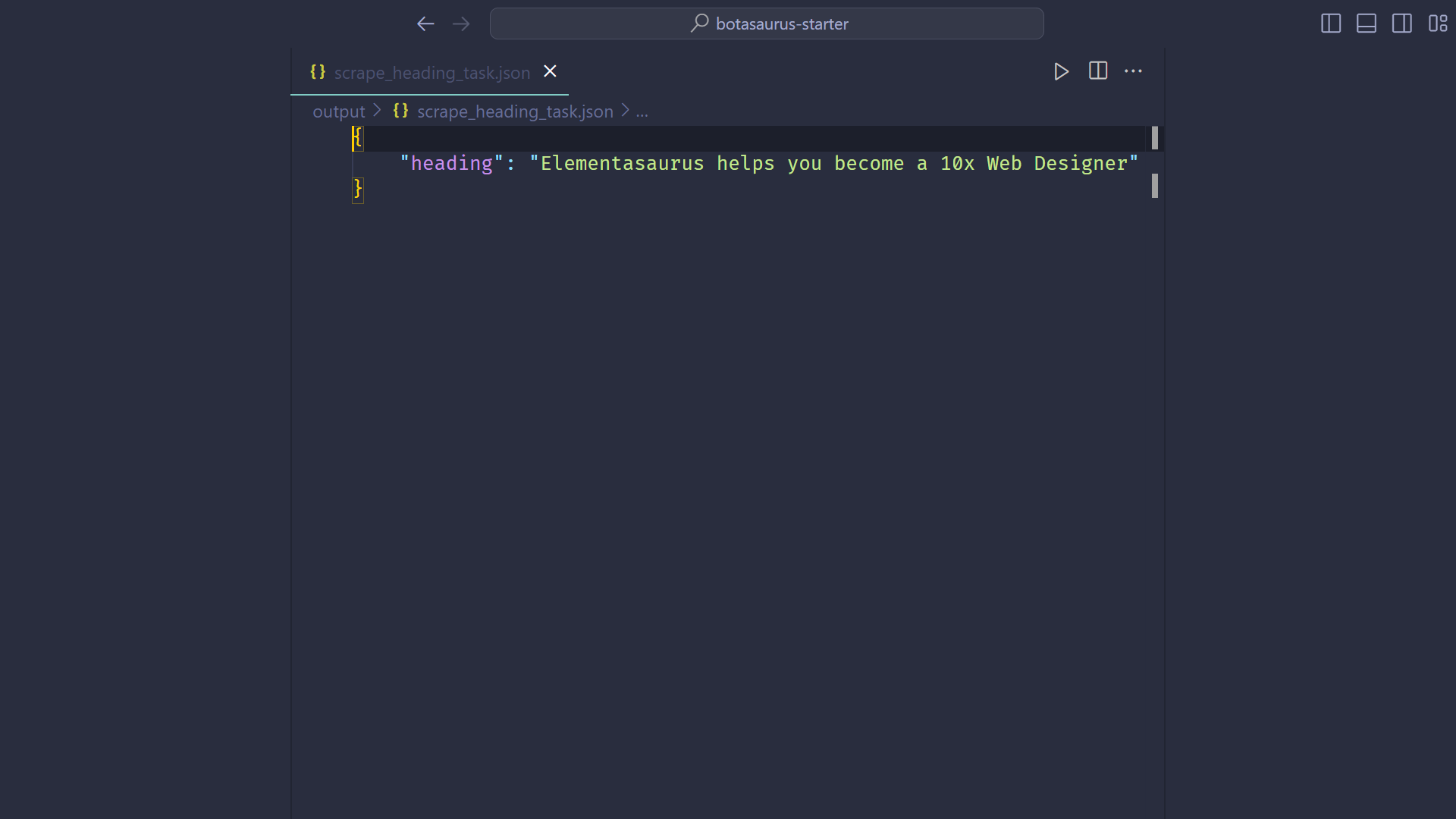
# Save the data as a JSON file in output/all.json
return {
"heading": heading
}
if __name__ == "__main__":
# Initiate the web scraping task
scrape_heading_task()
Let’s dissect this code:
- We define a custom scraping task,
scrape_heading_task, decorated with@browser:
@browser
def scrape_heading_task(driver: AntiDetectDriver, data):
- Botasaurus automatically provides an Anti Detection Selenium driver to our function:
def scrape_heading_task(driver: AntiDetectDriver, data):
- Inside the function, we:
- Navigate to Omkar Cloud
- Extract the heading text
- Prepare the data to be automatically saved as JSON and CSV files by Botasaurus:
driver.get("https://www.omkar.cloud/")
heading = driver.text("h1")
return {"heading": heading}
- Finally, we initiate the scraping task:
if __name__ == "__main__":
scrape_heading_task()
Step 4: Run the Scraping Task
Time to run your bot:
python main.py
After executing the script, it will:
- Launch Google Chrome
- Navigate to omkar.cloud
- Extract the heading text
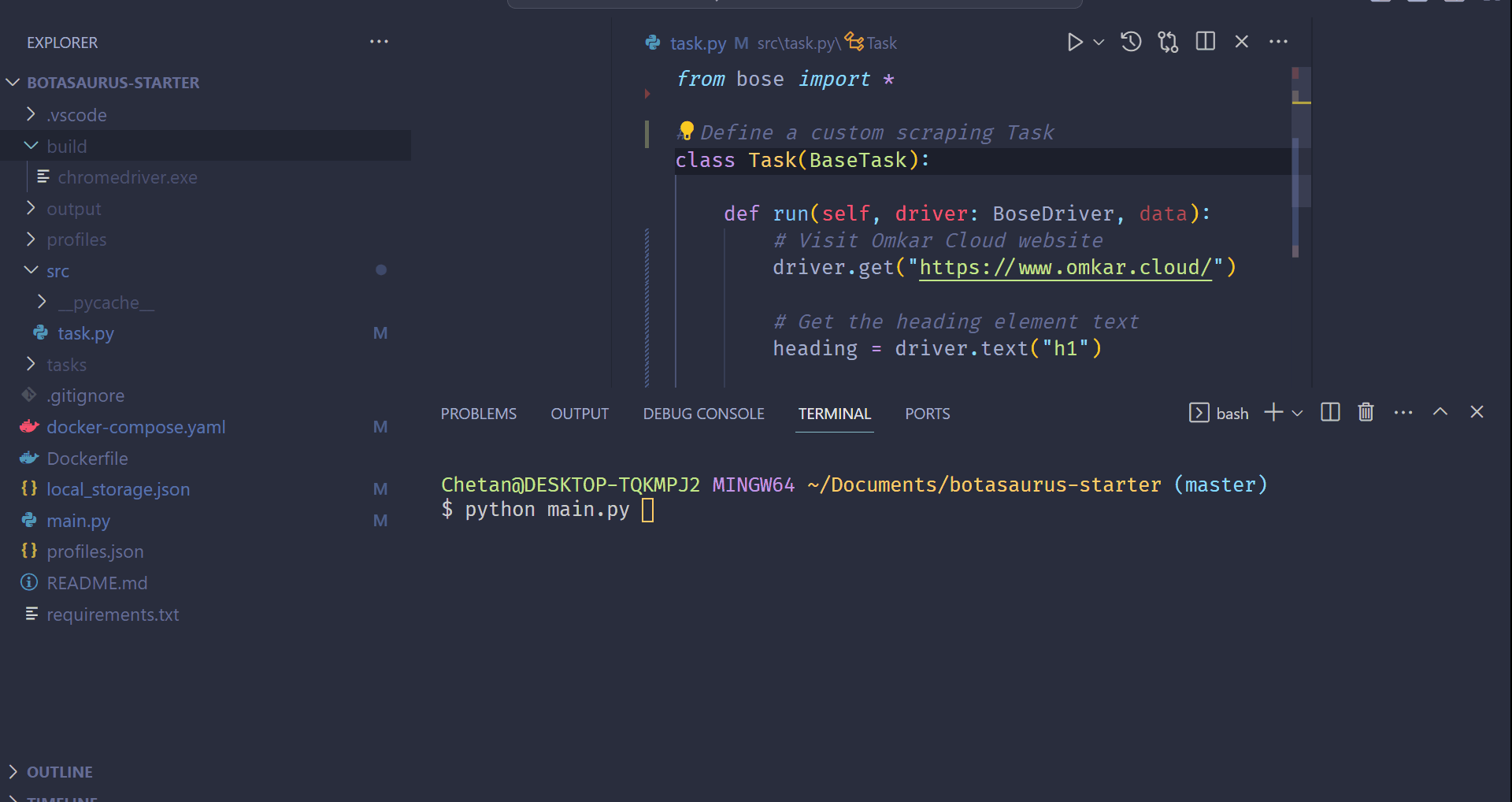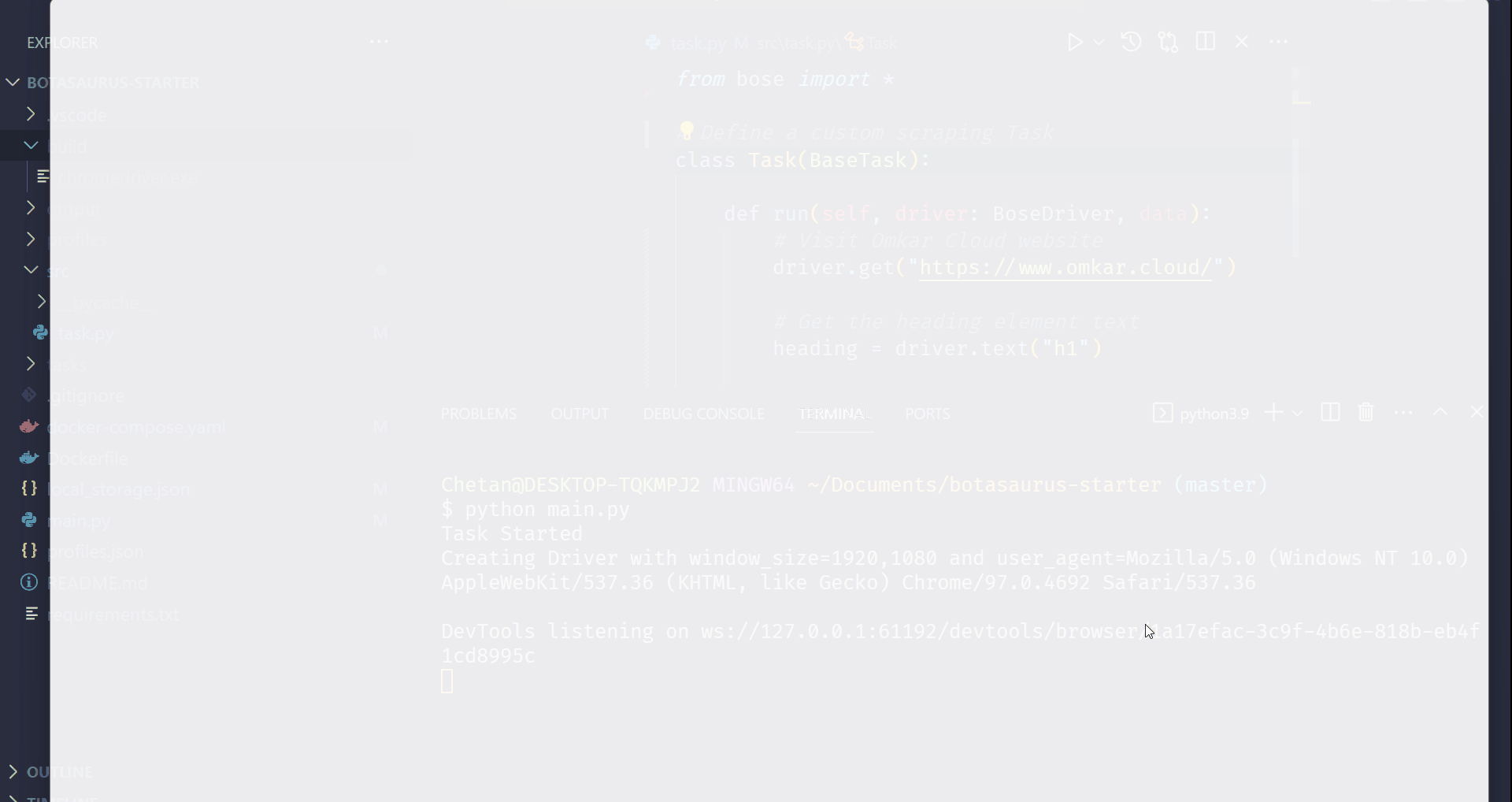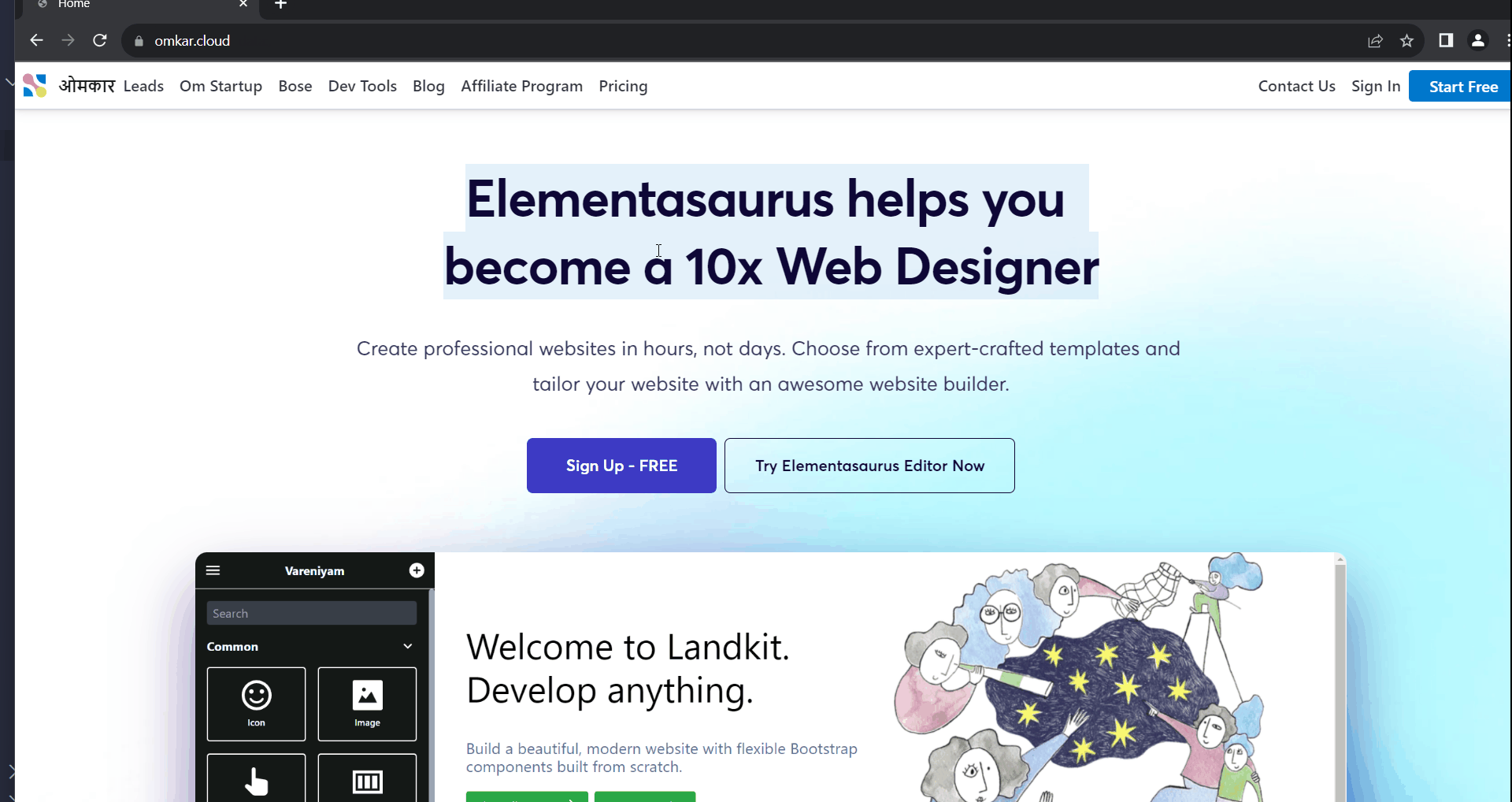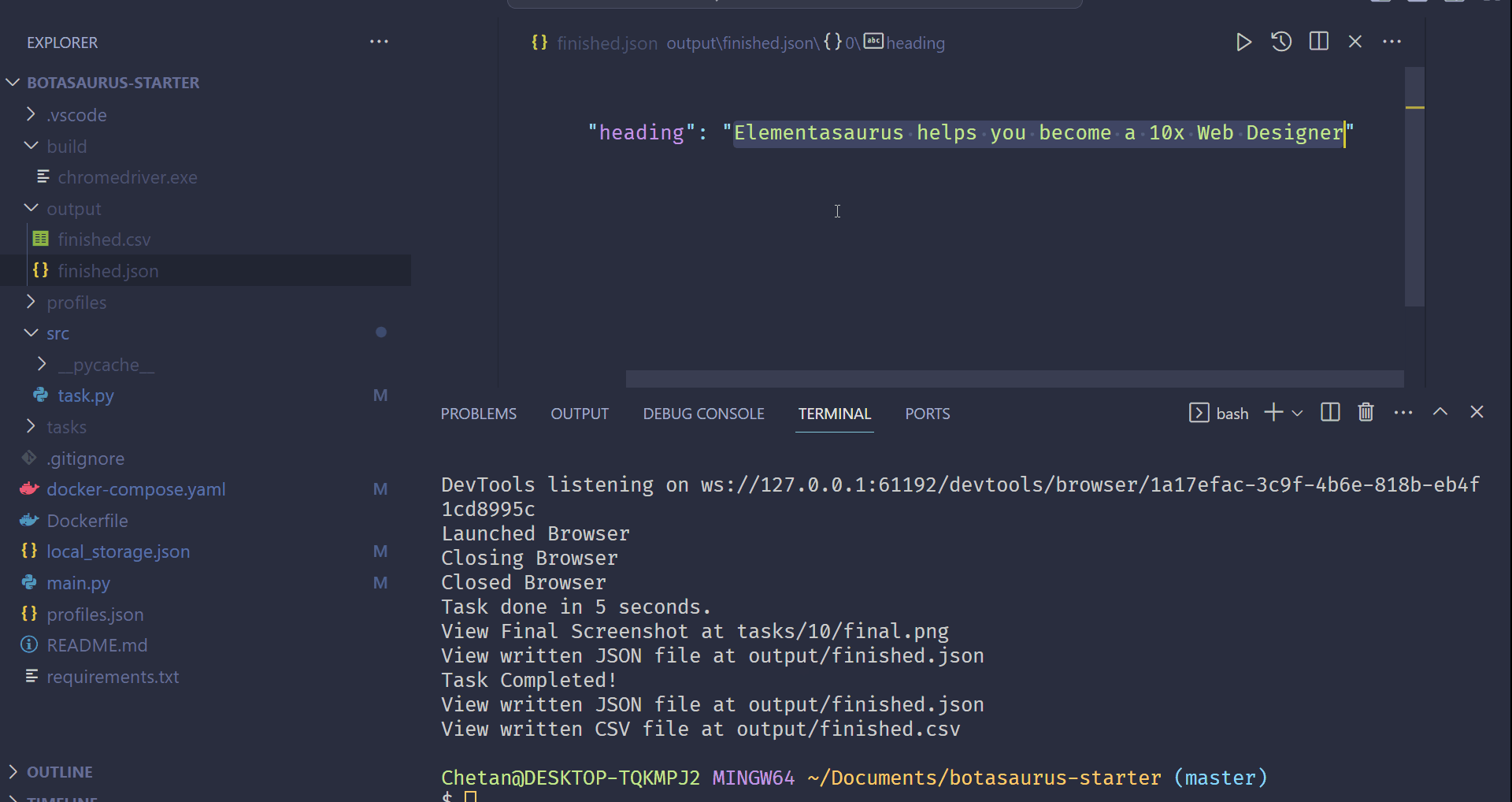
- Save it automatically as
output/finished.json.
Now, let’s explore another way to scrape the heading using the request module. Replace the previous code in main.py with the following:
from botasaurus import *
@request
def scrape_heading_task(request: AntiDetectRequests, data):
# Navigate to the Omkar Cloud website
soup = request.bs4("https://www.omkar.cloud/")
# Retrieve the heading element's text
heading = soup.find('h1').get_text()
# Save the data as a JSON file in output/all.json
return {
"heading": heading
}
if __name__ == "__main__":
# Initiate the web scraping task
scrape_heading_task()
In this code:
- We are using the BeautifulSoup (bs4) module to parse and scrape the heading.
- The
requestobject provided is not a standard Python request object but an Anti Detect request object, which also preserves cookies.
Step 5: Run the Scraping Task (Using Anti Detect Requests)
Finally, run the bot again:
python main.py
This time, you will observe the same result as before, but instead of using Anti Detect Selenium, we are utilizing the Anti Detect request module.
💡 Understanding Botasaurus
Let's learn about the features of Botasaurus that assist you in web scraping and automation.
How to Scrape Multiple Data Points/Links?
To scrape multiple data points or links, define the data variable and provide a list of items to be scraped:
@browser(data=["https://www.omkar.cloud/", "https://www.omkar.cloud/blog/", "https://stackoverflow.com/"])
def scrape_heading_task(driver: AntiDetectDriver, data):
# ...
Botasaurus will launch a new browser instance for each item in the list and merge and store the results in scrape_heading_task.json at the end of the scraping.
Please note that the data parameter can also handle items such as dictionaries.
@browser(data=[{"name": "Mahendra Singh Dhoni", ...}, {"name": "Virender Sehwag", ...}])
def scrape_heading_task(driver: AntiDetectDriver, data: dict):
# ...
How to Scrape in Parallel?
To scrape data in parallel, set the parallel option in the browser decorator:
@browser(parallel=3, data=["https://www.omkar.cloud/", ...])
def scrape_heading_task(driver: AntiDetectDriver, data):
# ...
How to know how many scrapers to run parallely?
To determine the optimal number of parallel scrapers, pass the bt.calc_max_parallel_browsers function, which calculates the maximum number of browsers that can be run in parallel based on the available RAM:
@browser(parallel=bt.calc_max_parallel_browsers, data=["https://www.omkar.cloud/", ...])
def scrape_heading_task(driver: AntiDetectDriver, data):
# ...
Example: If you have 5.8 GB of free RAM, bt.calc_max_parallel_browsers would return 10, indicating you can run up to 10 browsers in parallel.
How to Cache the Web Scraping Results?
To cache web scraping results and avoid re-scraping the same data, set cache=True in the decorator:
@browser(cache=True, data=["https://www.omkar.cloud/", ...])
def scrape_heading_task(driver: AntiDetectDriver, data):
# ...
How Botasaurus helps me in debugging?
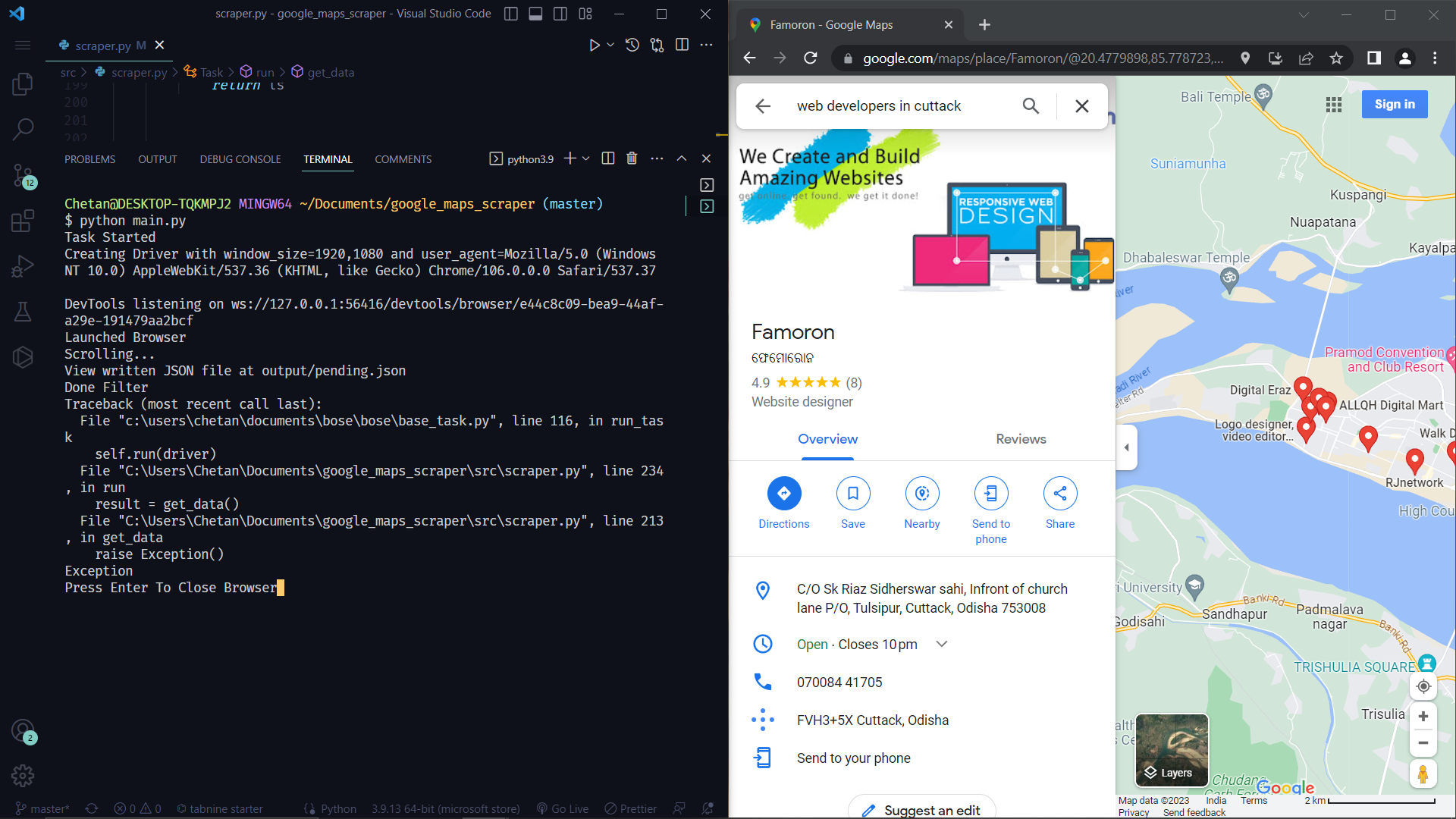
Botasaurus enhances the debugging experience by pausing the browser instead of closing it when an error occurs. This allows you to inspect the page and understand what went wrong, which can be especially helpful in debugging and removing the hassle of reproducing edge cases.
Botasaurus also plays a beep sound to alert you when an error occurs.
How to Block Images?
Blocking images can significantly speed up your web scraping tasks. For example, a page that originally takes 4 seconds to load might only take one second to load after images have been blocked.
To block images, simply set block_images=True in the decorator:
@browser(block_images=True)
def scrape_heading_task(driver: AntiDetectDriver, data):
# ...
How to Configure UserAgent, Proxy, Chrome Profile, Headless, etc.?
To configure various settings such as UserAgent, Proxy, Chrome Profile, and headless mode, you can specify them in the decorator as shown below:
@browser(
headless=True,
profile='my-profile',
proxy="http://your_proxy_address:your_proxy_port",
user_agent=bt.UserAgents.user_agent_106
)
def scrape_heading_task(driver: AntiDetectDriver, data):
# ...
How Can I Save Data With a Different Name Instead of 'all.json'?
To save the data with a different filename, pass the desired filename along with the data in a tuple as shown below:
@browser(block_images=True, cache=True)
def scrape_article_links(driver: AntiDetectDriver, data):
# Visit the Omkar Cloud website
driver.get("https://www.omkar.cloud/blog/")
links = driver.links("h3 a")
filename = "links"
return filename, links
I want to Scrape a large number of Links, a new selenium driver is getting created for each new link, this increases the time to scrape data. How can I reuse Drivers?
Utilize the reuse_driver option to reuse drivers, reducing the time required for data scraping:
@browser(reuse_driver=True)
def scrape_heading_task(driver: AntiDetectDriver, data):
# ...
Could you show me a practical example where all these Botasaurus Features Come Together to accomplish a typical web scraping project?
Below is a practical example of how Botasaurus features come together in a typical web scraping project to scrape a list of links from a blog, and then visit each link to retrieve the article's heading and date:
@browser(block_images=True,
cache=True,
parallel=bt.calc_max_parallel_browsers,
reuse_driver=True)
def scrape_articles(driver: AntiDetectDriver, link):
driver.get(link)
heading = driver.text("h1")
date = driver.text("time")
return {
"heading": heading,
"date": date,
"link": link,
}
@browser(block_images=True, cache=True)
def scrape_article_links(driver: AntiDetectDriver, data):
# Visit the Omkar Cloud website
driver.get("https://www.omkar.cloud/blog/")
links = driver.links("h3 a")
filename = "links"
return filename, links
if __name__ == "__main__":
# Launch the web scraping task
links = scrape_article_links()
scrape_articles(links)
How to Read/Write JSON and CSV Files?
Botasaurus provides convenient methods for reading and writing data:
# Data to write to the file
data = [
{"name": "John Doe", "age": 42},
{"name": "Jane Smith", "age": 27},
{"name": "Bob Johnson", "age": 35}
]
# Write the data to the file "data.json"
bt.write_json(data, "data.json")
# Read the contents of the file "data.json"
print(bt.read_json("data.json"))
# Write the data to the file "data.csv"
bt.write_csv(data, "data.csv")
# Read the contents of the file "data.csv"
print(bt.read_csv("data.csv"))
How Can I Pause the Scraper to Inspect Things While Developing?
To pause the scraper and wait for user input before proceeding, use bt.prompt():
bt.prompt()
How Does AntiDetectDriver Facilitate Easier Web Scraping?
AntiDetectDriver is a patched Version of Selenium that has been modified to avoid detection by bot protection services such as Cloudflare.
It also includes a variety of helper functions that make web scraping tasks easier.
You can learn about these methods here.
What Features Does @request Support, Similar to @browser?
Similar to @browser, @request supports features like
- asynchronous execution [Will Learn Later]
- parallel processing
- caching
- user-agent customization
- proxies, etc.
Below is an example that showcases these features:
@request(parallel=40, cache=True, proxy="http://your_proxy_address:your_proxy_port", data=["https://www.omkar.cloud/", ...])
def scrape_heading_task(request: AntiDetectDriver, link):
soup = request.bs4(link)
heading = soup.find('h1').get_text()
return {"heading": heading}
I have an existing project into which I want to integrate the AntiDetectDriver/AntiDetectRequests.
You can create an instance of AntiDetectDriver as follows:
driver = bt.create_driver()
# ... Code for scraping
driver.quit()
You can create an instance of AntiDetectRequests as follows:
anti_detect_request = bt.create_request()
soup = anti_detect_request.bs4("https://www.omkar.cloud/")
# ... Additional code
How to Run Botasaurus in Docker?
To run Botasaurus in Docker, use the Botasaurus Starter Template, which includes the necessary Dockerfile and Docker Compose configurations:
git clone https://github.com/omkarcloud/botasaurus-starter my-botasaurus-project
cd my-botasaurus-project
docker-compose build && docker-compose up
How to Run Botasaurus in Gitpod?
Botasaurus Starter Template comes with the necessary .gitpod.yml to easily run it in Gitpod, a browser-based development environment. Set it up in just 5 minutes by following these steps:
Open Botasaurus Starter Template, by visiting this link and sign up using your GitHub account.

To speed up scraping, select the Large 8 Core, 16 GB Ram Machine and click the
Continuebutton.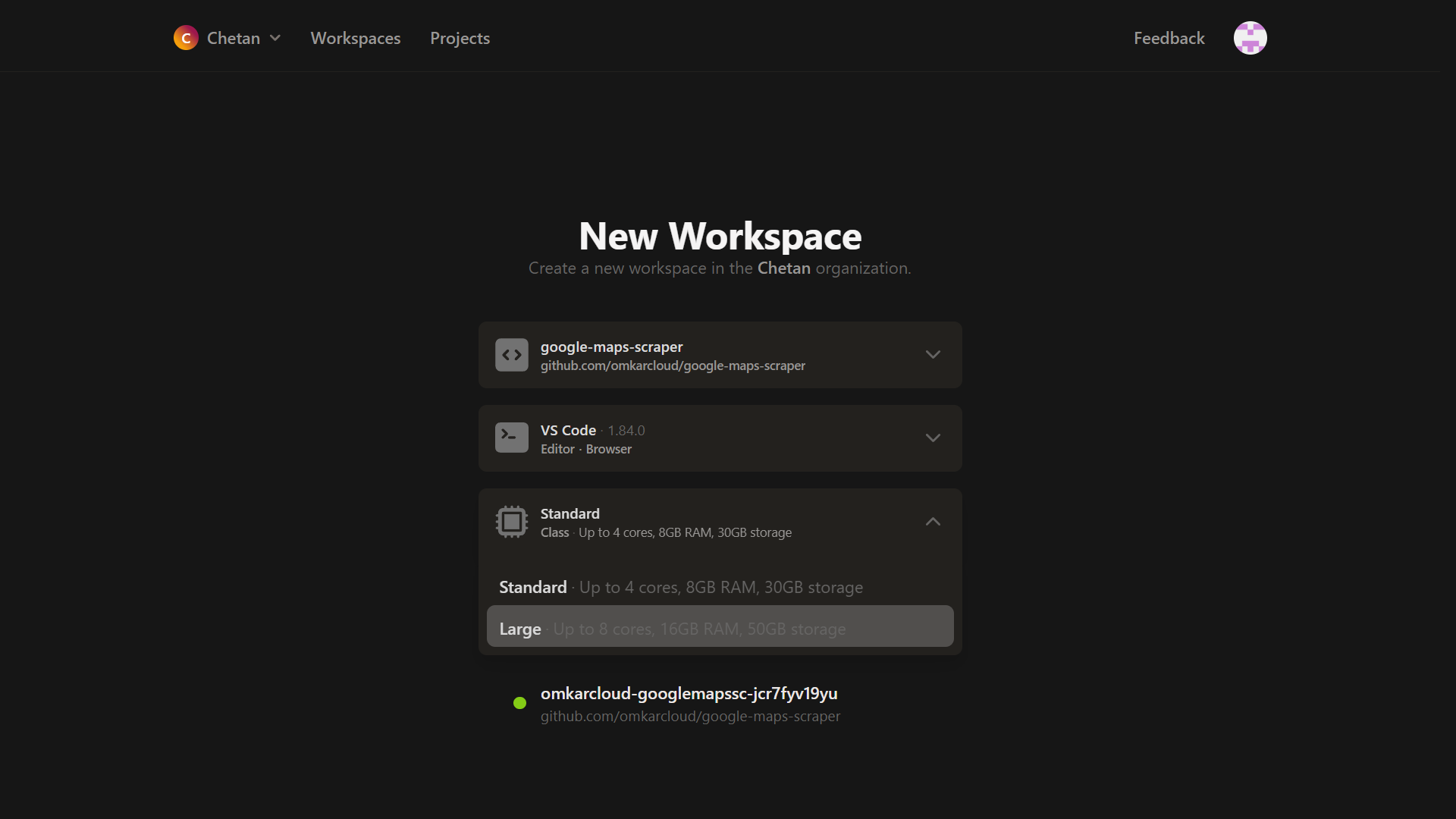
In the terminal, run the following command to start scraping:
python main.py
Please understand:
The internet speed in Gitpod is extremely fast at around 180 Mbps.
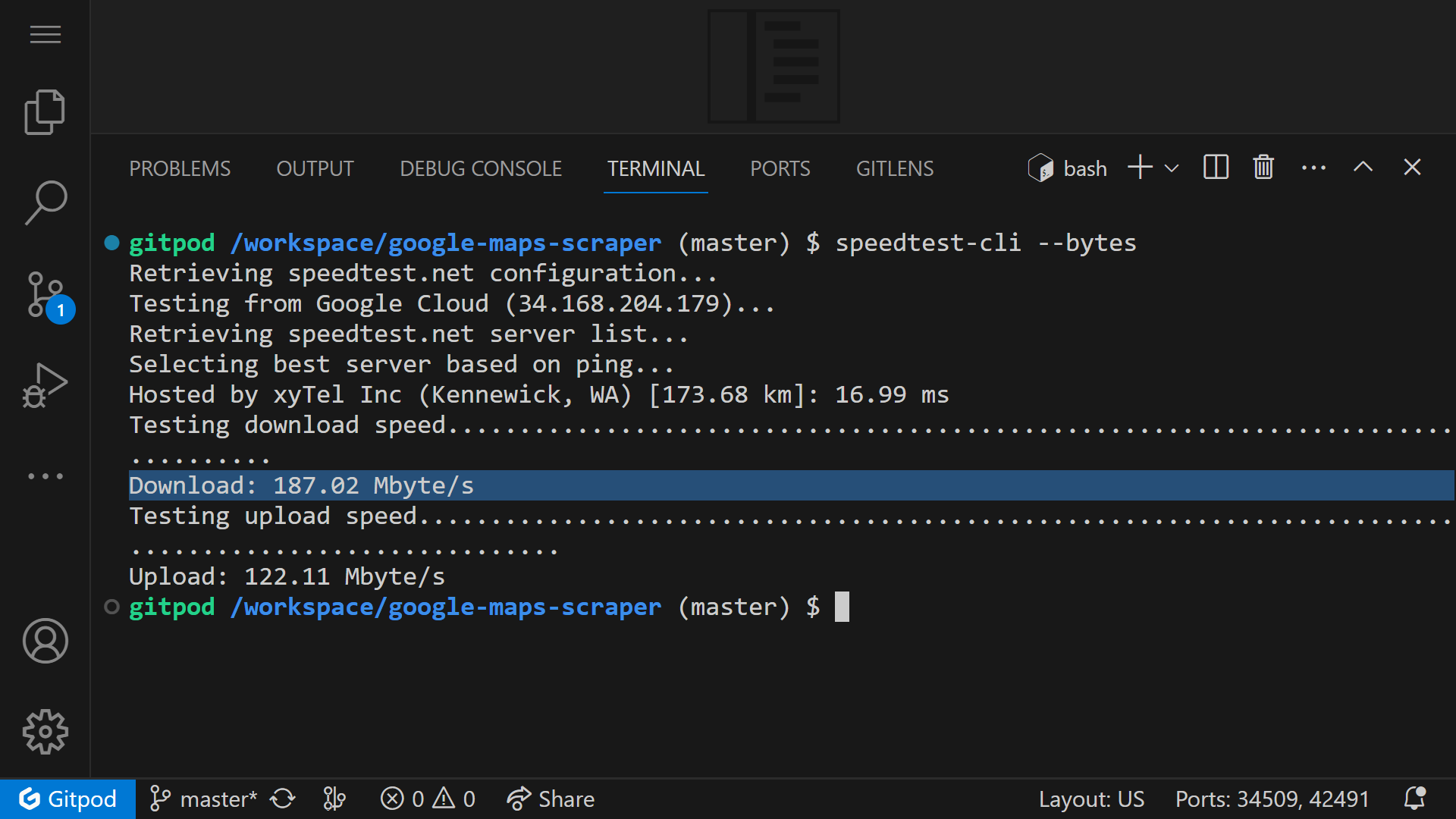
When Scraping, You need to interact with Gitpod, such as clicking within the environment, every 30 minutes to prevent the machine from automatically closing.
Advanced Features
How Do I Configure the Output of My Scraping Function in Botasaurus?
To configure the output of your scraping function in Botasaurus, you can customize the behavior in several ways:
Change Output Filename: Use the
outputparameter in the decorator to specify a custom filename for the output.@browser(output="my-output")
def scrape_heading_task(driver: AntiDetectDriver, data):
# Your scraping logic hereDisable Output: If you don't want any output to be saved, set
outputtoNone.@browser(output=None)
def scrape_heading_task(driver: AntiDetectDriver, data):
# Your scraping logic hereDynamically Write Output: To dynamically write output based on data and result, pass a function to the
outputparameter:def write_output(data, result):
bt.write_json(result, 'data')
bt.write_csv(result, 'data')
@browser(output=write_output)
def scrape_heading_task(driver: AntiDetectDriver, data):
# Your scraping logic hereSave Outputs in Multiple Formats: Use the
output_formatsparameter to save outputs in different formats like CSV and JSON.@browser(output_formats=[bt.Formats.CSV, bt.Formats.JSON])
def scrape_heading_task(driver: AntiDetectDriver, data):
# Your scraping logic here
These options provide flexibility in how you handle the output of your scraping tasks with Botasaurus.
How to Run Drivers Asynchronously from the Main Process?
To execute drivers asynchronously, enable the async option and use .get() when you're ready to collect the results:
from time import sleep
@browser(
run_async=True, # Specify the Async option here
)
def scrape_heading(driver: AntiDetectDriver, data):
print("Sleeping for 5 seconds.")
sleep(5)
print("Slept for 5 seconds.")
return {}
if __name__ == "__main__":
# Launch web scraping tasks asynchronously
result1 = scrape_heading() # Launches asynchronously
result2 = scrape_heading() # Launches asynchronously
result1.get() # Wait for the first result
result2.get() # Wait for the second result
With this method, function calls run concurrently. The output will indicate that both function calls are executing in parallel.
How to Asynchronously Add Multiple Items and Get Results?
The async_queue feature allows you to perform web scraping tasks in asyncronously in a queue, without waiting for each task to complete before starting the next one. To gather your results, simply use the .get() method when all tasks are in the queue.
Basic Example:
from time import sleep
from your_scraping_library import browser, AntiDetectDriver # Replace with your actual scraping library
@browser(async_queue=True)
def scrape_data(driver: AntiDetectDriver, data):
print("Starting a task.")
sleep(1) # Simulate a delay, e.g., waiting for a page to load
print("Task completed.")
return data
if __name__ == "__main__":
# Start scraping tasks without waiting for each to finish
async_queue = scrape_data() # Initializes the queue
# Add tasks to the queue
async_queue.put([1, 2, 3])
async_queue.put(4)
async_queue.put([5, 6])
# Retrieve results when ready
results = async_queue.get() # Expects to receive: [1, 2, 3, 4, 5, 6]
Practical Application for Web Scraping:
Here's how you could use async_queue to scrape webpage titles while scrolling through a list of links:
from your_scraping_library import browser, AntiDetectDriver # Replace with your actual scraping library
@browser(async_queue=True)
def scrape_title(driver: AntiDetectDriver, link):
driver.get(link) # Navigate to the link
return driver.title # Scrape the title of the webpage
@browser()
def scrape_all_titles(driver: AntiDetectDriver):
# ... Your code to visit the initial page ...
title_queue = scrape_title() # Initialize the asynchronous queue
while not end_of_page_detected(driver): # Replace with your end-of-list condition
title_queue.put(driver.links('a')) # Add each link to the queue
driver.scroll(".scrollable-element")
return title_queue.get() # Get all the scraped titles at once
if __name__ == "__main__":
all_titles = scrape_all_titles() # Call the function to start the scraping process
Note: The async_queue will only invoke the scraping function for unique links, avoiding redundant operations and keeping the main function (scrape_all_titles) cleaner.
I want to repeatedly call the scraping function without creating new Selenium drivers each time. How can I achieve this?
Utilize the keep_drivers_alive option to maintain active driver sessions. Remember to call .close() when you're finished to release resources:
@browser(
keep_drivers_alive=True,
parallel=bt.calc_max_parallel_browsers, # Typically used with `keep_drivers_alive`
reuse_driver=True, # Also commonly paired with `keep_drivers_alive`
)
def scrape_data(driver: AntiDetectDriver, data):
# ... (Your scraping logic here)
if __name__ == "__main__":
for i in range(3):
scrape_data()
# After completing all scraping tasks, call .close() to close the drivers.
scrape_data.close()
How do I manage the Cache in Botasaurus?
You can use The Cache Module in Botasaurus to easily manage cached data. Here's a simple example explaining its usage:
from botasaurus import *
from botasaurus.cache import Cache
# Example scraping function
@request
def scrape_data(data):
# Your scraping logic here
return {"processed": data}
# Sample data for scraping
input_data = {"key": "value"}
# Adding data to the cache
Cache.put(scrape_data, input_data, scrape_data(input_data))
# Checking if data is in the cache
if Cache.has(scrape_data, input_data):
# Retrieving data from the cache
cached_data = Cache.get(scrape_data, input_data)
# Removing specific data from the cache
Cache.remove(scrape_data, input_data)
# Clearing the complete cache for the scrape_data function
Cache.clear(scrape_data)
Conclusion
Botasaurus is a powerful, flexible tool for web scraping.
Its various settings allow you to tailor the scraping process to your specific needs, improving both efficiency and convenience. Whether you're dealing with multiple data points, requiring parallel processing, or need to cache results, Botasaurus provides the features to streamline your scraping tasks.