Google Maps Scraping Tutorial
🏗️ What Are We Building?
In this tutorial, we will be Scraping Google Maps for Leads.
By scraping Google Maps, we can access the phone numbers and websites of businesses. This invaluable data allows us to reach out and promote our products effectively.
In this tutorial, not only will you develop a practical scraping tool, but you will also gain hands-on experience in:
- Running bots in parallel for faster scraping.
- Understanding the overall process of a web scraping project with Botasaurus.
- Saving the extracted data in both CSV and JSON formats.
- Setting up your scraper in a Docker environment for consistent and reproducible execution.
Now that you have an overview of what's in store, let's start building!
🛠️ How Are We Gonna Build That?
Let's break down the steps to build our Google Maps scraper with Botasaurus:
Create a new project using the
botasaurus-startertemplate.Then, we'll visit the search query page.

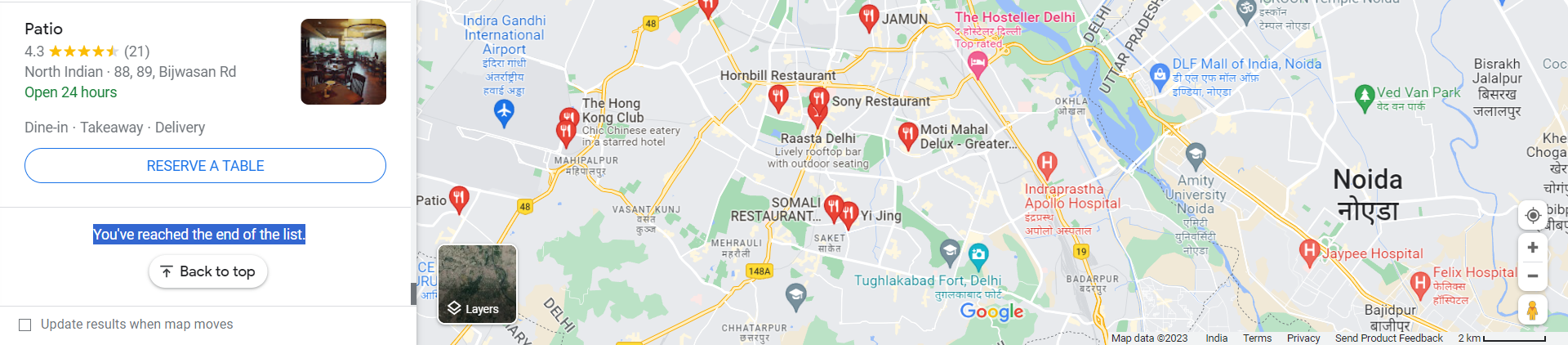
Next, we'll scroll through the list of places until we've scrolled to the end of the list.
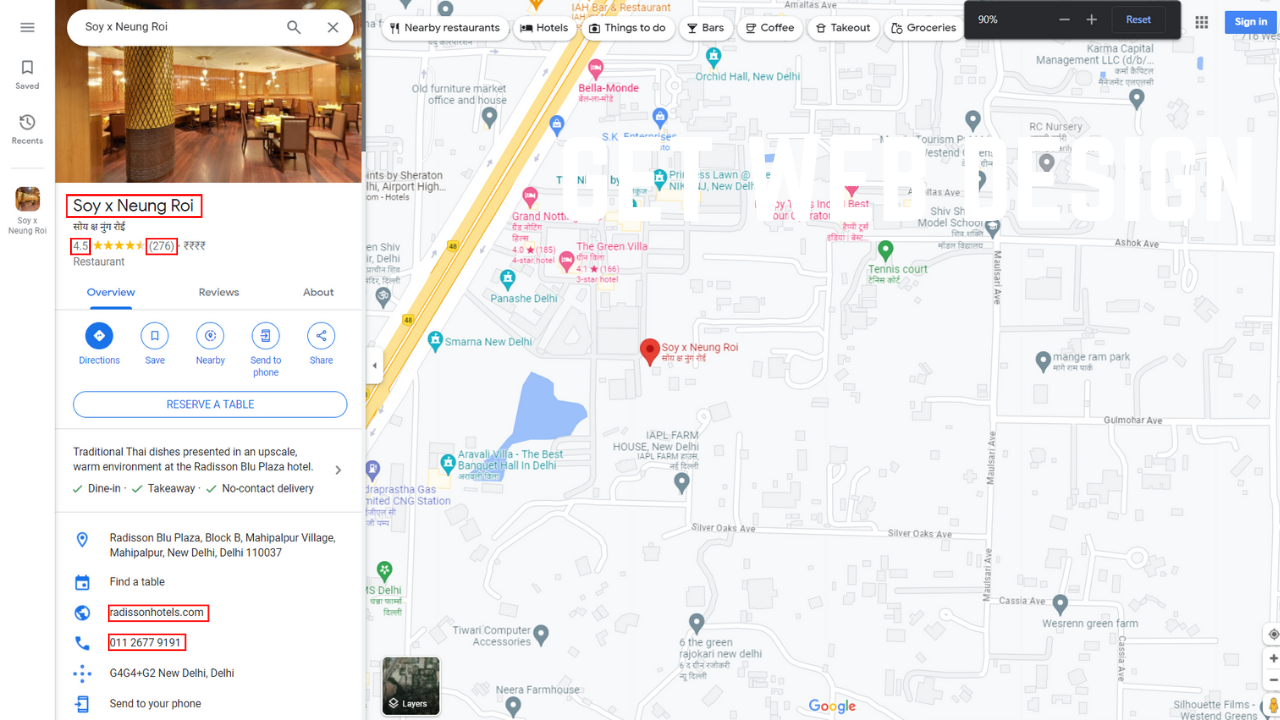
We will extract all links, then visit each place and extract the data.
To speed up the scraping of places, we'll run multiple bots in parallel.
We'll block images to ensure the pages load faster.
Then, we will run the Bot using Python.
Lastly, we'll run the Scraper in Docker.
Shall we begin :)?
🏭 Setting Up the Project
To kickstart our Google Maps scraping project, we recommend using the Botasaurus Starter Template.
It's the recommended way for creating greenfield Botasaurus projects because it includes all the necessary boilerplate code, .gitignore, and Docker files.
This lets you dive right into developing your bot without any setup hassles.
Here's the quick setup process:
1. Clone the Starter Template:
Clone the Botasaurus Starter Template:
git clone https://github.com/omkarcloud/botasaurus-starter my-botasaurus-project
2. Navigate and Prepare:
Move to the project directory:
cd my-botasaurus-project
If you prefer Visual Studio Code for development, open the project in Visual Studio Code:
code .
With these steps, your project will be set up for writing code.
🔍 Searching for Places
In this step, we'll walk you through implementing the search functionality on Google Maps. It's a straightforward process with a few key steps:
1. Define Your Search Queries
Begin by specifying the search queries that will help you find the places you're interested in. In our example, we're looking for "restaurants in delhi."
2. Construct the Search Page URL
To initiate the search, you need to create the appropriate URL. In our case, it takes the form of https://www.google.com/maps/search/restaurants+in+delhi/.
3. Visit the Search Page
Next, we'll visit the created search page URL.
4. Accept Cookies For European Users
European users may encounter a form to accept cookies. We've also added code to accept the cookies:
Implementing this code is simple:
@browser(
data=["restaurants in delhi"],
)
def scrape_places_links(driver: AntiDetectDriver, query):
# Visit Google Maps
def visit_google_maps():
encoded_query = urllib.parse.quote_plus(query)
url = f'https://www.google.com/maps/search/{encoded_query}'
driver.get(url)
# Accept Cookies for European users
if driver.is_in_page("https://consent.google.com/"):
agree_button_selector = 'form:nth-child(2) > div > div > button'
driver.click(agree_button_selector)
driver.google_get(url)
visit_google_maps()
With the provided code, we have successfully implemented the search functionality part of the project.
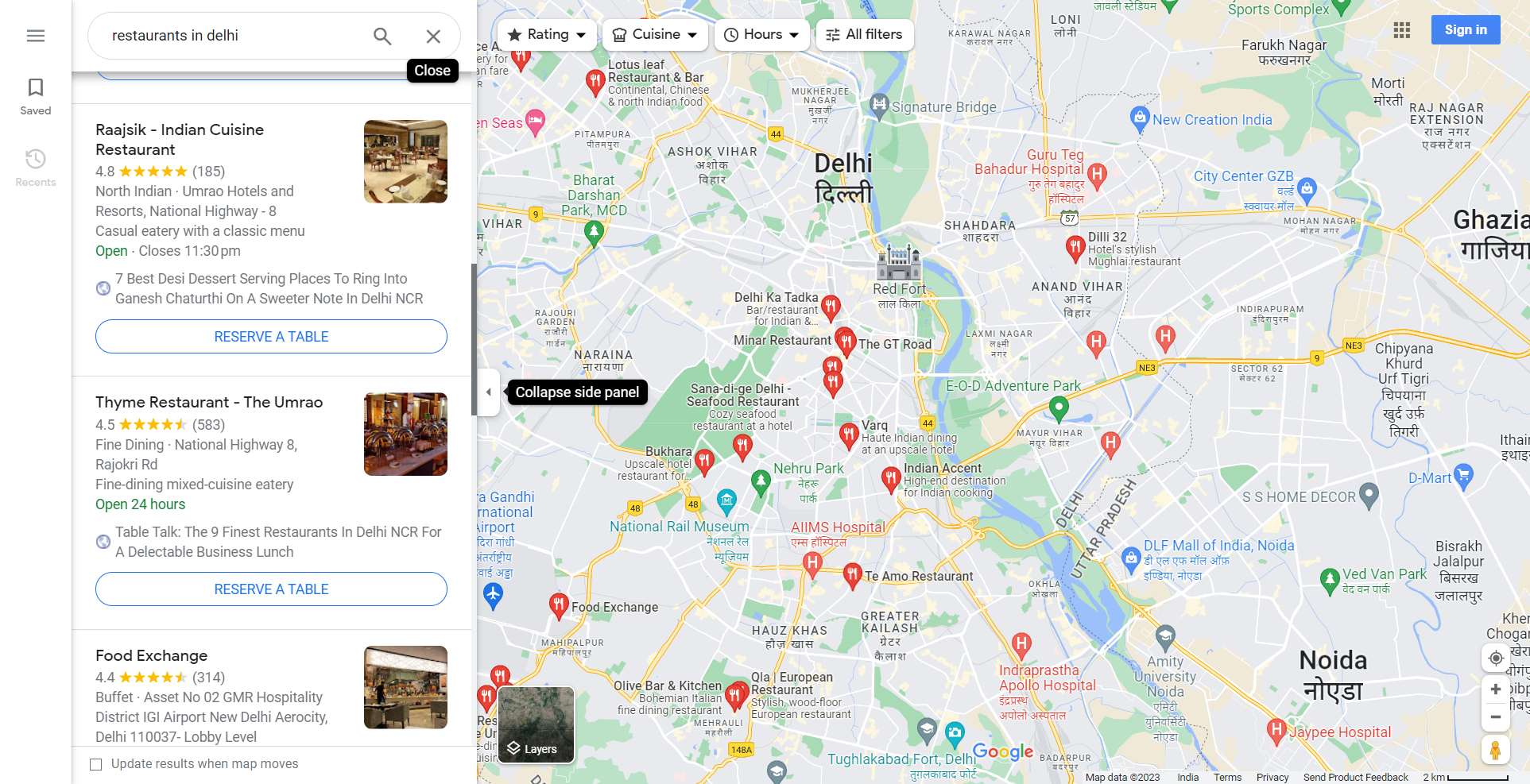
🔄 Scrolling to the End of the Places List
When scraping places from Google Maps, the search results are presented in a list that loads dynamically as you scroll.
Therefore, to access all the places listed, our bot must scroll to the very end of this list.
To do this, we will keep scrolling until we reach the end of the list. When we reach the end of the list, Google Maps will display a message to indicate there are no more places to load.
We can check the visibility of this message element to stop scrolling.
Let's see this in code:
# Scroll to the end of the places list to get all the places
def scroll_to_end_of_places_list():
end_of_list_detected = False
while not end_of_list_detected:
# Element that holds the list of places
places_list_element_selector = '[role="feed"]'
driver.scroll(places_list_element_selector)
print('Scrolling...')
# Check if we've reached the end of the list
end_of_list_indicator_selector = "p.fontBodyMedium > span > span"
if driver.exists(end_of_list_indicator_selector):
end_of_list_detected = True
print("Successfully scrolled to the end of the places list.")
📦 Extracting Data
Once you've scrolled to the end of the list, the next step is to extract the required data. The process comprises:
- Extracting all links pointing to individual places (e.g., "google.com/maps/place/Indian+Accent" or "google.com/maps/place/Rajasthan+in+delhi-Restaurant").
- Extracting the required data from each place.
Let's walk through the process:
Extract All Links
First, we will gather all the links pointing to the details of individual places. These links lead to pages containing more detailed information about each place.
def extract_place_links():
places_links_selector = '[role="feed"] > div > div > a'
return driver.links(places_links_selector)
Visit Each Link and Extract Data
For each extracted link, we will navigate to the page and scrape information about the place.
# Visit an individual place and extract data
def scrape_place_data():
driver.get(link)
# Accept Cookies for European users
if driver.is_in_page("https://consent.google.com/"):
agree_button_selector = 'form:nth-child(2) > div > div > button'
driver.click(agree_button_selector)
driver.get(link)
# Extract title
title_selector = 'h1'
title = driver.text(title_selector)
# Extract rating
rating_selector = "div.F7nice > span"
rating = driver.text(rating_selector)
# Extract reviews count
reviews_selector = "div.F7nice > span:last-child"
reviews_text = driver.text(reviews_selector)
reviews = int(''.join(filter(str.isdigit, reviews_text))) if reviews_text else None
# Extract website link
website_selector = "a[data-item-id='authority']"
website = driver.link(website_selector)
# Extract phone number
phone_xpath = "//button[starts-with(@data-item-id,'phone')]"
phone_element = driver.get_element_or_none(phone_xpath)
phone = phone_element.get_attribute("data-item-id").replace("phone:tel:", "") if phone_element else None
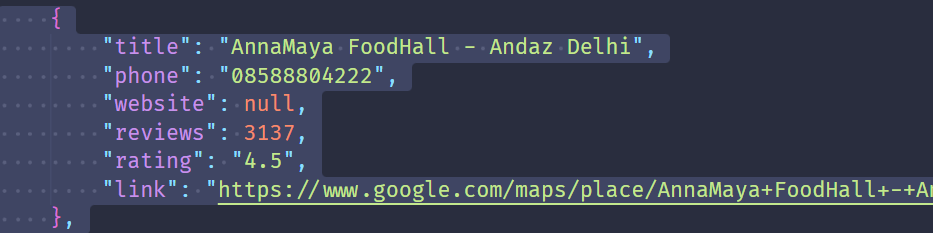
return {
"title": title,
"phone": phone,
"website": website,
"reviews": reviews,
"rating": rating,
"link": link,
}
With this, you've successfully extracted the required data for each place from Google Maps.
⚡ Speeding Up with Parallelism
Don't worry, if terms like async, parallelism, and concurrency sound intimidating to you, running bots in parallel is very simple in Botasaurus.
To speed up our scraping process, we'll employ parallelism by running multiple bots simultaneously.
Implementing parallelism in Botasaurus is as simple as 2 lines of code:
@browser(
parallel=bt.calc_max_parallel_browsers,
reuse_driver=True, # Reuse the browsers for scraping links
)
def scrape_places(driver: AntiDetectDriver, link):
🚫 Blocking Images
Loading image resources can:
- Significantly increase the cost of running the bot, especially if you're using residential proxies, which can be very expensive, costing around $15/GB.
- Slow down the scraping process, notably when interacting with media-rich sites like Google Maps.
Fortunately, we can enhance the cost efficiency and speed of our scraper by blocking images from loading.
In Botasaurus, you can easily configure the browser used by your bot to block images. Here's the simple code to do so:
@browser(
block_images=True,
)
🚀 Launch It
Now, it's time to launch the bot and see it in action!
Running the Bot
- In the repository cloned earlier, open
task.pyand paste the following code.
import botasaurus as bt
import urllib.parse
@browser(
block_images=True,
parallel=bt.calc_max_parallel_browsers,
reuse_driver=True,
)
def scrape_places(driver: AntiDetectDriver, link):
# Visit an individual place and extract data
def scrape_place_data():
driver.get(link)
# Accept Cookies for European users
if driver.is_in_page("https://consent.google.com/"):
agree_button_selector = 'form:nth-child(2) > div > div > button'
driver.click(agree_button_selector)
driver.get(link)
# Extract title
title_selector = 'h1'
title = driver.text(title_selector)
# Extract rating
rating_selector = "div.F7nice > span"
rating = driver.text(rating_selector)
# Extract reviews count
reviews_selector = "div.F7nice > span:last-child"
reviews_text = driver.text(reviews_selector)
reviews = int(''.join(filter(str.isdigit, reviews_text))
) if reviews_text else None
# Extract website link
website_selector = "a[data-item-id='authority']"
website = driver.link(website_selector)
# Extract phone number
phone_xpath = "//button[starts-with(@data-item-id,'phone')]"
phone_element = driver.get_element_or_none(phone_xpath)
phone = phone_element.get_attribute(
"data-item-id").replace("phone:tel:", "") if phone_element else None
return {
"title": title,
"phone": phone,
"website": website,
"reviews": reviews,
"rating": rating,
"link": link,
}
return scrape_place_data()
@browser(
data=["restaurants in delhi"],
block_images=True,
)
def scrape_places_links(driver: AntiDetectDriver, query):
# Visit Google Maps
def visit_google_maps():
encoded_query = urllib.parse.quote_plus(query)
url = f'https://www.google.com/maps/search/{encoded_query}'
driver.get(url)
# Accept Cookies for European users
if driver.is_in_page("https://consent.google.com/"):
agree_button_selector = 'form:nth-child(2) > div > div > button'
driver.click(agree_button_selector)
driver.google_get(url)
# Scroll to the end of the places list to get all the places
def scroll_to_end_of_places_list():
end_of_list_detected = False
while not end_of_list_detected:
# Element that holds the list of places
places_list_element_selector = '[role="feed"]'
driver.scroll(places_list_element_selector)
print('Scrolling...')
# Check if we've reached the end of the list
end_of_list_indicator_selector = "p.fontBodyMedium > span > span"
if driver.exists(end_of_list_indicator_selector):
end_of_list_detected = True
print("Successfully scrolled to the end of the places list.")
def extract_place_links():
places_links_selector = '[role="feed"] > div > div > a'
return driver.links(places_links_selector)
visit_google_maps()
scroll_to_end_of_places_list()
# Get all place links
places_links = extract_place_links()
# Return the places links to be saved as a output/links file
filename = 'links'
return filename, places_links
if __name__ == "__main__":
links = scrape_places_links()
scrape_places(links)
- Run your scraper, by executing the following command:
python main.py
After you run the command, you'll see your bot visiting Google Maps, scrolling through the places list, visiting each place, and extracting the required data.
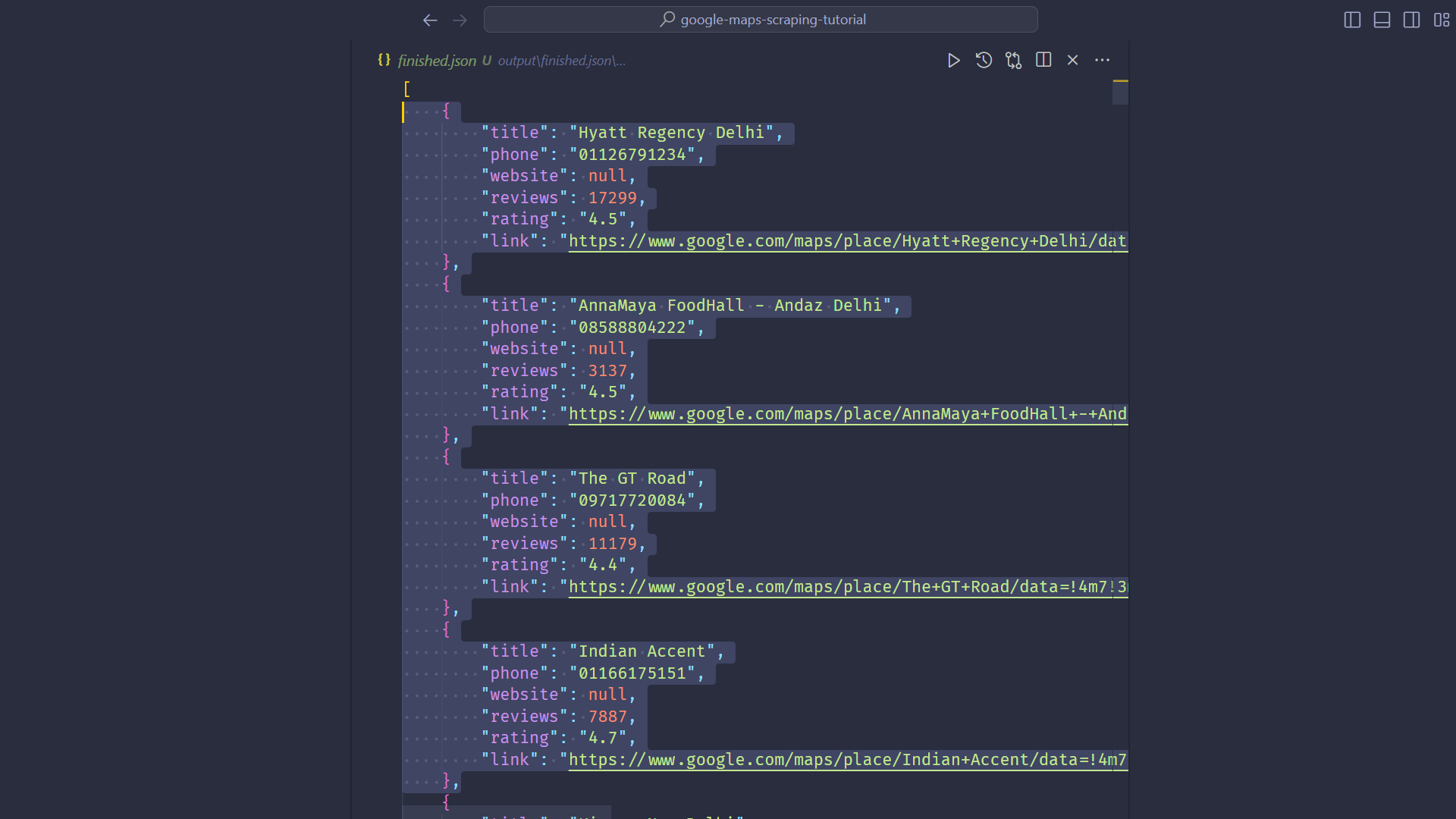
Checking the Output
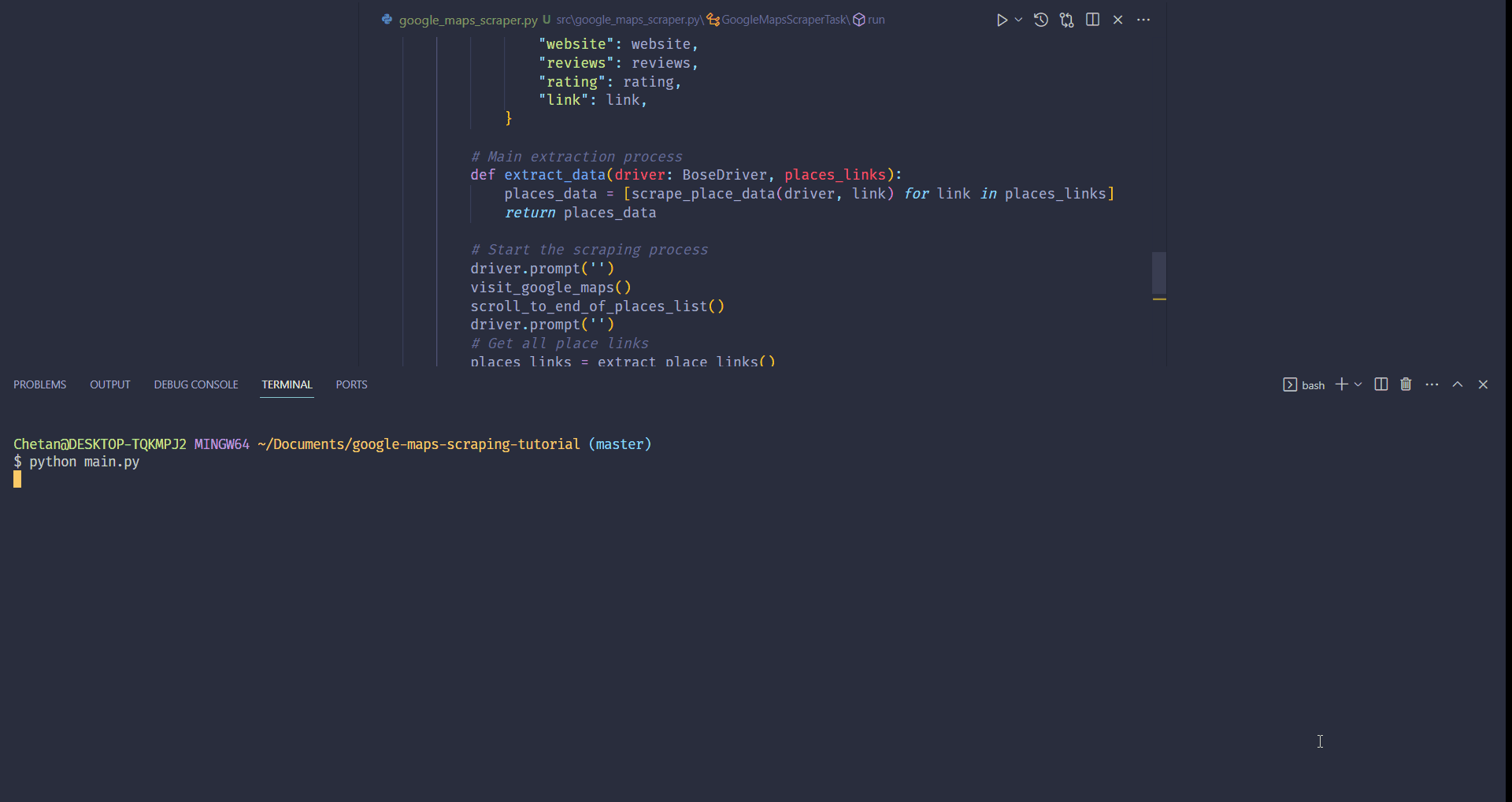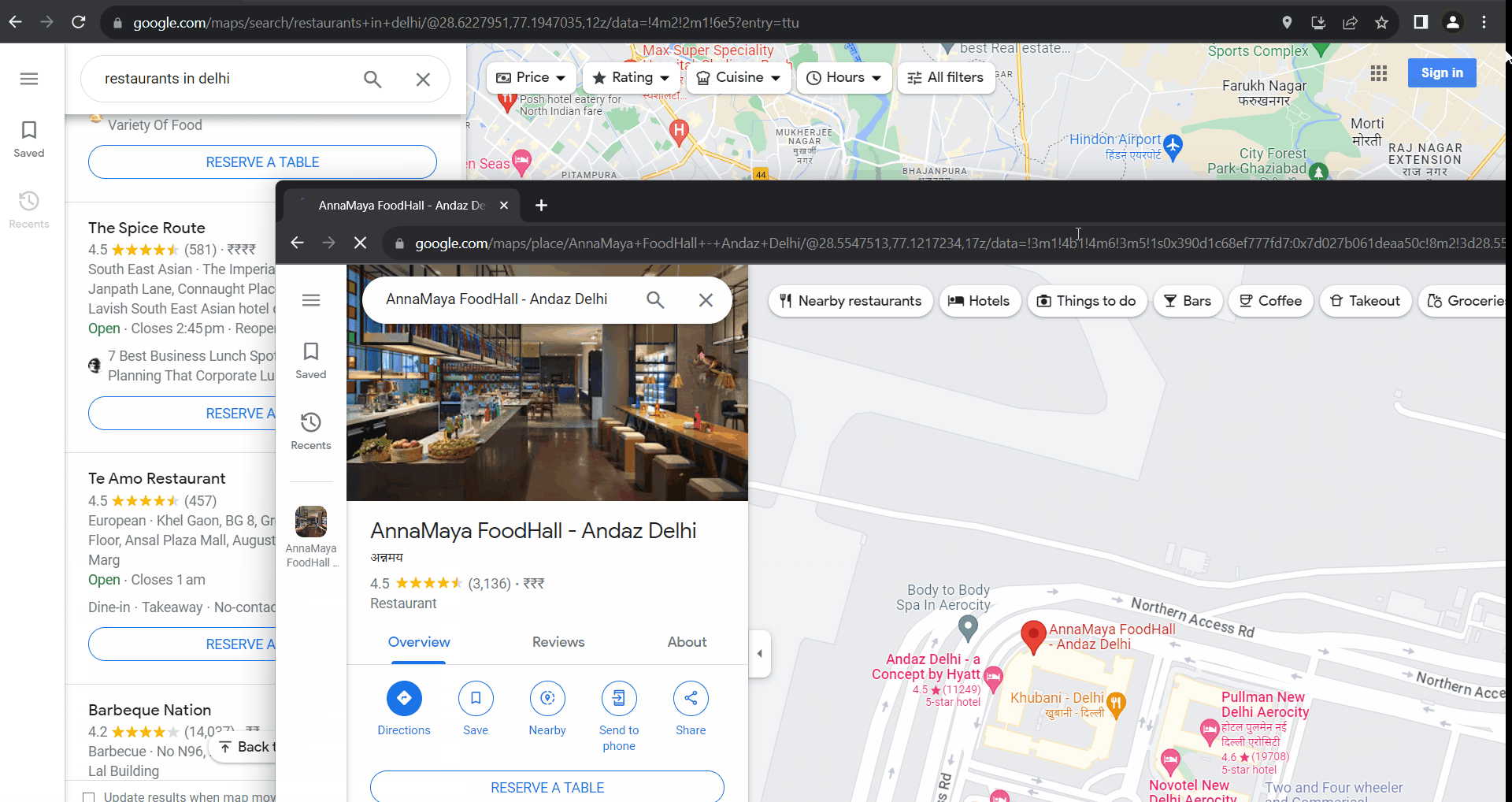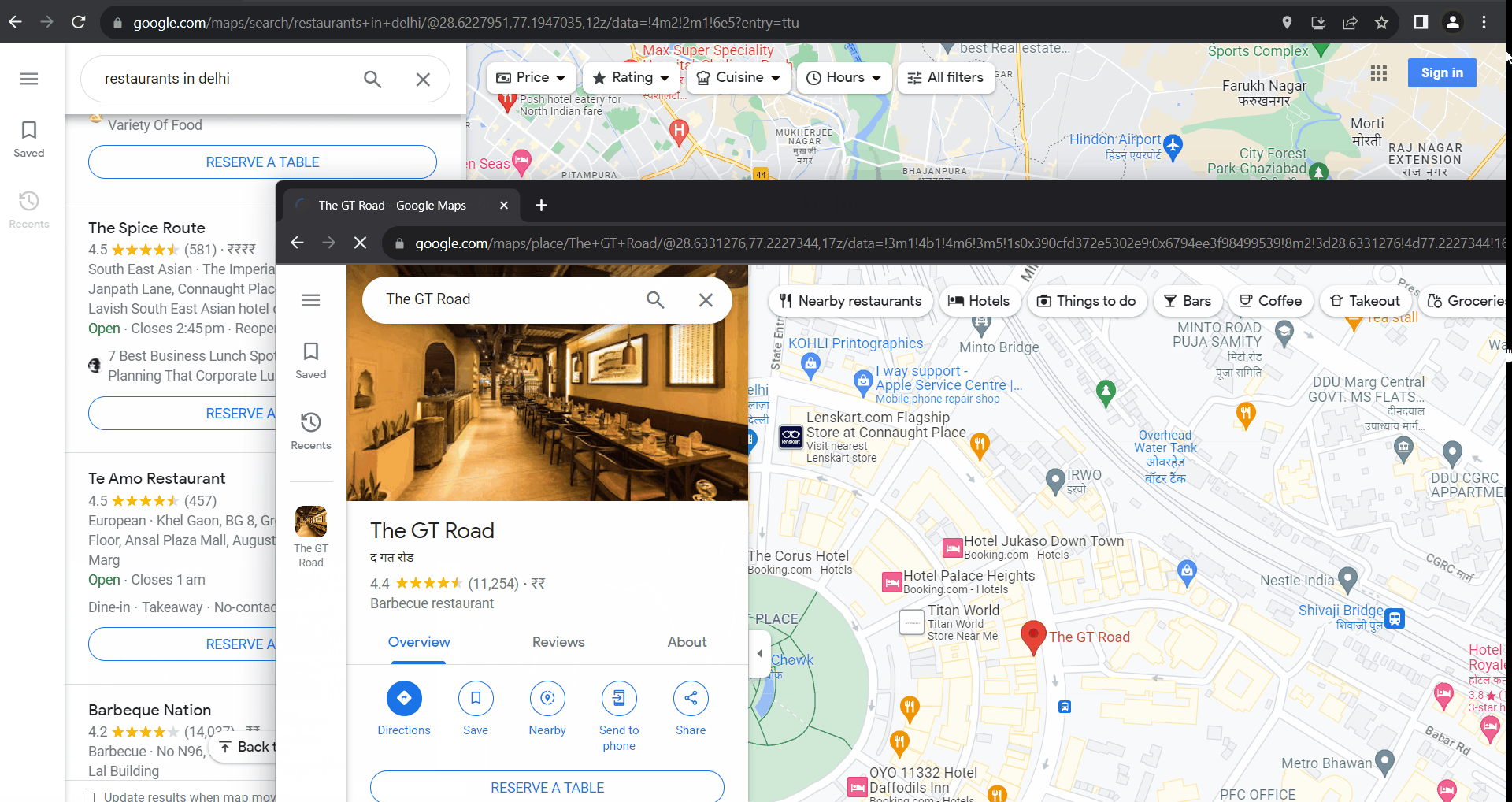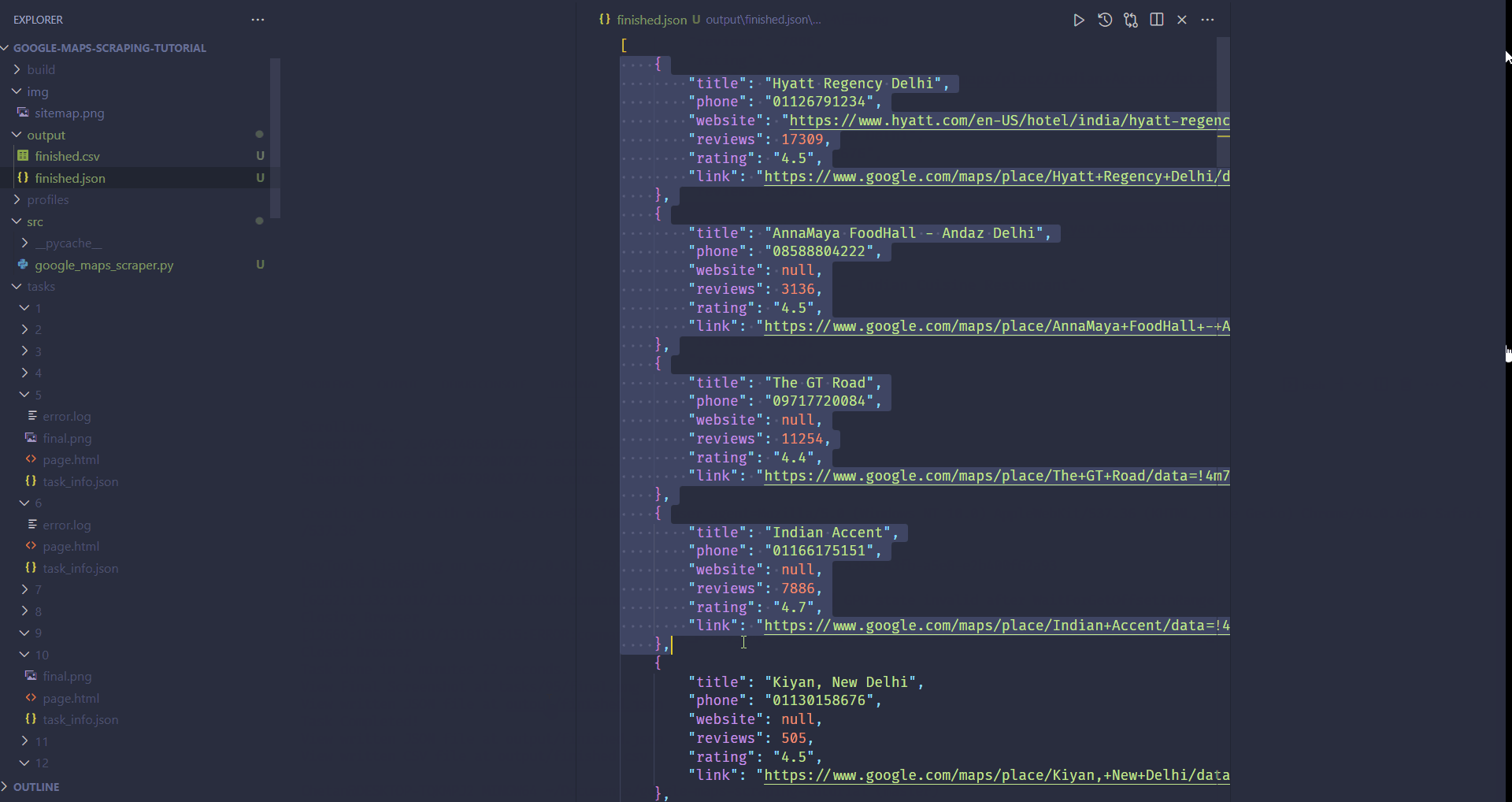
After the bot finishes running, the extracted data will be stored in the output folder. Specifically, look for the finished.json file.
🐳 Dockerization
Docker enables the encapsulation of an application along with its dependencies. This ensures consistent and reproducible execution across various platforms, such as EC2, Cloud Engine, and others.
Additionally, it also helps in reducing vendor lock-in.
Thankfully, our botasaurus-starter already comes with a Dockerfile and a docker-compose.yml file, making the dockerization process easy.
To run your scraper inside a Docker container, execute the following command:
docker-compose build && docker-compose up
It's important to note that you need to rebuild the Docker image every time you want to run your scraper. Ensure you execute the above command to both rebuild and run your scraper inside Docker.
We've developed an advanced, production-ready version of the scraper that's 4x faster and handles many edge cases. For simplicity, these cases weren't covered in this tutorial. We recommend using this enhanced version over the one built in the tutorial. You can access it here.
🎉 What's Next?
Congrats! You've built a powerful Google Maps scraper and mastered Botasaurus. Now, it's time to unleash your bot-building skills in the real world!